
前沿拓展:
推荐学习22天试水Python社招,历经“百度+字节+天融”等6家 金三即过,这300道python高频面试都没刷,银四怎么闯? 

前言
Logging日志记录框架是Python内置打印模块,它对很多Python开发者来说是既熟悉又陌生,确实,它使用起来很简单,只需要我们简单一行代码,就可以打印出日志
import logging
logging.debug("This is a debug log.")
logging.info("This is a info log.")
logging.warning("This is a warning log.")
logging.error("This is a error log.")
logging.critical("This is a critical log.")
# output
WARNING:root:This is a warning log.
ERROR:root:This is a error log.
CRITICAL:root:This is a critical log.
但是对于我们在实际项目中需要基于Logging来开发日志框架时,常常会遇到各种各样的问题,例如性能方面的多进程下滚动日志记录丢失、日志记录效率低的问题以及在二次开发时因为没有理解Logging内部流程导致没有利用到Logging的核心机制等等。
接下来,我们就从一行代码来深挖Logging System的秘密
1. 深入Logging模块源码1.1 logging.info做了什么?
logging.info作为大多数人使用logging模块的第一行代码,隐藏了很多实现细节,以至于我们在最初都只关注功能,而忽略了它的内部细节
import logging
logging.info("This is a info log.")
# logging/__init__.py
def info(msg, *args, **kwargs):
"""
Log a message with severity 'INFO' on the root logger. If the logger has
no handlers, call basicConfig() to add a console handler with a pre-defined
format.
"""
# 没有绑定handlers就调用basicConfig方法
if len(root.handlers) == 0:
basicConfig()
root.info(msg, *args, **kwargs)
_lock = threading.RLock()
def _acquireLock():
"""
Acquire the module-level lock for serializing access to shared data.
This should be released with _releaseLock().
"""
if _lock:
_lock.acquire()
def _releaseLock():
"""
Release the module-level lock acquired by calling _acquireLock().
"""
if _lock:
_lock.release()
def basicConfig(**kwargs):
"""
很方便的一步到位的配置方法创建一个StreamHandler打印日志到控制台
This function does nothing if the root logger already has handlers
configured. It is a convenience method intended for use by simple scripts
to do one-shot configuration of the logging package.
The default behaviour is to create a StreamHandler which writes to
sys.stderr, set a formatter using the BASIC_FORMAT format string, and
add the handler to the root logger.
"""
# Add thread safety in case someone mistakenly calls
# basicConfig() from multiple threads
# 为了确保多线程安全的写日志**作,做了加锁处理(如上,标准的多线程锁**作)
_acquireLock()
try:
if len(root.handlers) == 0:
# 对于handler的处理,有filename就新建FileHandler,没有就选择StreamHandler
handlers = kwargs.pop("handlers", None)
if handlers is None:
if "stream" in kwargs and "filename" in kwargs:
raise ValueError("'stream' and 'filename' should not be "
"specified together")
else:
if "stream" in kwargs or "filename" in kwargs:
raise ValueError("'stream' or 'filename' should not be "
"specified together with 'handlers'")
if handlers is None:
filename = kwargs.pop("filename", None)
mode = kwargs.pop("filemode", 'a')
if filename:
h = FileHandler(filename, mode)
else:
stream = kwargs.pop("stream", None)
h = StreamHandler(stream)
handlers = [h]
dfs = kwargs.pop("datefmt", None)
style = kwargs.pop("style", '%')
if style not in _STYLES:
raise ValueError('Style must be one of: %s' % ','.join(
_STYLES.keys()))
fs = kwargs.pop("format", _STYLES[style][1])
fmt = Formatter(fs, dfs, style)
# 绑定handler到root
for h in handlers:
if h.formatter is None:
h.setFormatter(fmt)
root.addHandler(h)
level = kwargs.pop("level", None)
if level is not None:
root.setLevel(level)
if kwargs:
keys = ', '.join(kwargs.keys())
raise ValueError('Unrecognised argument(s): %s' % keys)
finally:
_releaseLock()
到目前为止,可以看到logging.info通过调用basicConfig()来完成初始化handler之后才开始正式打印,而basicConfig()的逻辑是通过多线程锁状态下的一个初始化handler->绑定root的**作,那这个root代表了什么呢?
# logging/__init__.py
root = RootLogger(WARNING)
Logger.root = root
Logger.manager = Manager(Logger.root)
class RootLogger(Logger):
"""
A root logger is not that different to any other logger, except that
it must have a logging level and there is only one instance of it in
the hierarchy.
"""
def __init__(self, level):
"""
Initialize the logger with the name "root".
"""
# 调用父类的初始化,传入了root和WARNING两个参数,所以我们直接调用logging.info时是不能输出任何信息的,因为logger level初始化时就被指定成了WARNING
Logger.__init__(self, "root", level)
def __reduce__(self):
return getLogger, ()
class Logger(Filterer):
"""
Instances of the Logger class represent a single logging channel. A
"logging channel" indicates an area of an application. Exactly how an
"area" is defined is up to the application developer. Since an
application can have any number of areas, logging channels are identified
by a unique string. Application areas can be nested (e.g. an area
of "input processing" might include sub-areas "read CSV files", "read
XLS files" and "read Gnumeric files"). To cater for this natural nesting,
channel names are organized into a namespace hierarchy where levels are
separated by periods, much like the Java or Python package namespace. So
in the instance given above, channel names might be "input" for the upper
level, and "input.csv", "input.xls" and "input.gnu" for the sub-levels.
There is no arbitrary limit to the depth of nesting.
"""
def __init__(self, name, level=NOTSET):
"""
Initialize the logger with a name and an optional level.
"""
Filterer.__init__(self)
self.name = name # 指定name,也就是之前的root
self.level = _checkLevel(level) # 指定logger level
self.parent = None
self.propagate = True
self.handlers = []
self.disabled = False
self._cache = {}
def info(self, msg, *args, **kwargs):
"""
Log 'msg % args' with severity 'INFO'.
To pass exception information, use the keyword argument exc_info with
a true value, e.g.
logger.info("Houston, we have a %s", "interesting problem", exc_info=1)
"""
# 这步判断是为了判断是否该logger level可以被输出
if self.isEnabledFor(INFO):
self._log(INFO, msg, args, **kwargs)
def getEffectiveLevel(self):
"""
Get the effective level for this logger.
Loop through this logger and its parents in the logger hierarchy,
looking for a non-zero logging level. Return the first one found.
"""
# 寻找父级logger level
logger = self
while logger:
if logger.level:
return logger.level
logger = logger.parent
return NOTSET
def isEnabledFor(self, level):
"""
Is this logger enabled for level 'level'?
"""
try:
return self._cache[level]
except KeyError:
# 又出现的加锁**作
_acquireLock()
if self.manager.disable >= level:
is_enabled = self._cache[level] = False
else:
is_enabled = self._cache[level] = level >= self.getEffectiveLevel()
_releaseLock()
return is_enabled
root是RootLogger的实例,RootLogger继承于Logger,通过_log来统一记录日志,而在_log之前会有个logger level的判断
# 用来获取堆栈中的第一个调用者
# _srcfile is used when walking the stack to check when we've got the first
# caller stack frame, by skipping frames whose filename is that of this
# module's source. It therefore should contain the filename of this module's
# source file.
#
# Ordinarily we would use __file__ for this, but frozen modules don't always
# have __file__ set, for some reason (see Issue #21736). Thus, we get the
# filename from a handy code object from a function defined in this module.
# (There's no particular reason for picking addLevelName.)
#
_srcfile = os.path.normcase(addLevelName.__code__.co_filename)
# _srcfile is only used in conjunction with sys._getframe().
# To provide compatibility with older versions of Python, set _srcfile
# to None if _getframe() is not available; this value will prevent
# findCaller() from being called. You can also do this if you want to avoid
# the overhead of fetching caller information, even when _getframe() is
# available.
#if not hasattr(sys, '_getframe'):
# _srcfile = None
def _log(self, level, msg, args, exc_info=None, extra=None, stack_info=False):
"""
Low-level logging routine which creates a LogRecord and then calls
all the handlers of this logger to handle the record.
"""
sinfo = None
if _srcfile:
#IronPython doesn't track Python frames, so findCaller raises an
#exception on some versions of IronPython. We trap it here so that
#IronPython can use logging.
try:
fn, lno, func, sinfo = self.findCaller(stack_info)
except ValueError: # pragma: no cover
fn, lno, func = "(unknown file)", 0, "(unknown function)"
else: # pragma: no cover
fn, lno, func = "(unknown file)", 0, "(unknown function)"
if exc_info:
if isinstance(exc_info, BaseException):
exc_info = (type(exc_info), exc_info, exc_info.__traceback__)
elif not isinstance(exc_info, tuple):
exc_info = sys.exc_info()
# 通过makeRecord生成一条日志记录
record = self.makeRecord(self.name, level, fn, lno, msg, args,
exc_info, func, extra, sinfo)
# 处理
self.handle(record)
def findCaller(self, stack_info=False):
"""
通过调用堆栈获取文件名、行数和调用者
Find the stack frame of the caller so that we can note the source
file name, line number and function name.
"""
f = currentframe()
#On some versions of IronPython, currentframe() returns None if
#IronPython isn't run with -X:Frames.
if f is not None:
f = f.f_back
rv = "(unknown file)", 0, "(unknown function)", None
while hasattr(f, "f_code"):
co = f.f_code
filename = os.path.normcase(co.co_filename)
if filename == _srcfile:
f = f.f_back
continue
sinfo = None
if stack_info:
sio = io.StringIO()
sio.write('Stack (most recent call last):n')
traceback.print_stack(f, file=sio)
sinfo = sio.getvalue()
if sinfo[-1] == 'n':
sinfo = sinfo[:-1]
sio.close()
rv = (co.co_filename, f.f_lineno, co.co_name, sinfo)
break
return rv
def makeRecord(self, name, level, fn, lno, msg, args, exc_info,
func=None, extra=None, sinfo=None):
"""
A factory method which can be overridden in subclasses to create
specialized LogRecords.
"""
# 生成_logRecordFactory的实例
rv = _logRecordFactory(name, level, fn, lno, msg, args, exc_info, func,
sinfo)
if extra is not None:
for key in extra:
if (key in ["message", "asctime"]) or (key in rv.__dict__):
raise KeyError("Attempt to overwrite %r in LogRecord" % key)
rv.__dict__[key] = extra[key]
return rv
def handle(self, record):
"""
Call the handlers for the specified record.
This method is used for unpickled records received from a socket, as
well as those created locally. Logger-level filtering is applied.
"""
if (not self.disabled) and self.filter(record):
self.callHandlers(record)
def callHandlers(self, record):
"""
Pass a record to all relevant handlers.
Loop through all handlers for this logger and its parents in the
logger hierarchy. If no handler was found, output a one-off error
message to sys.stderr. Stop searching up the hierarchy whenever a
logger with the "propagate" attribute set to zero is found – that
will be the last logger whose handlers are called.
"""
c = self
found = 0
# 轮询自身绑定的handlers,并调用handle方法来处理该record实例,这里有点类似于import的流程,调用sys.meta_path的importer来处理path,也是同样的道理,这里我们回忆之前的rootLogger,我们调用baseConfig来初始化使FileHandler绑定到root,第二调用root.info,最终就来到了这个方法,调用到了FileHandler.handle方法来处理
while c:
for hdlr in c.handlers:
found = found + 1
if record.levelno >= hdlr.level:
hdlr.handle(record)
if not c.propagate:
c = None #break out
else:
c = c.parent
if (found == 0):
if lastResort:
if record.levelno >= lastResort.level:
lastResort.handle(record)
elif raiseExceptions and not self.manager.emittedNoHandlerWarning:
sys.stderr.write("No handlers could be found for logger"
" "%s"n" % self.name)
self.manager.emittedNoHandlerWarning = True
继续来看FileHandler
class FileHandler(StreamHandler):
def _open(self):
"""
Open the current base file with the (original) mode and encoding.
Return the resulting stream.
"""
return open(self.baseFilename, self.mode, encoding=self.encoding)
def emit(self, record):
"""
Emit a record.
If the stream was not opened because 'delay' was specified in the
constructor, open it before calling the superclass's emit.
"""
# 打开文件句柄(文件流)
if self.stream is None:
self.stream = self._open()
# 调用StreamHandler的emit方法
StreamHandler.emit(self, record)
class StreamHandler(Handler):
def flush(self):
"""
Flushes the stream.
"""
# 同样时加锁刷入
self.acquire()
try:
if self.stream and hasattr(self.stream, "flush"):
self.stream.flush()
finally:
self.release()
def emit(self, record):
"""
Emit a record.
If a formatter is specified, it is used to format the record.
The record is then written to the stream with a trailing newline. If
exception information is present, it is formatted using
traceback.print_exception and appended to the stream. If the stream
has an 'encoding' attribute, it is used to determine how to do the
output to the stream.
"""
try:
msg = self.format(record)
stream = self.stream
# issue 35046: merged two stream.writes into one.
# 写入流的缓冲区,执行flush
stream.write(msg + self.terminator)
self.flush()
except RecursionError: # See issue 36272
raise
except Exception:
self.handleError(record)
class Handler(Filterer):
# FileHandler的handle方法来源于祖父辈的Handler
def filter(self, record):
"""
Determine if a record is loggable by consulting all the filters.
The default is to allow the record to be logged; any filter can veto
this and the record is then dropped. Returns a zero value if a record
is to be dropped, else non-zero.
.. versionchanged:: 3.2
Allow filters to be just callables.
"""
rv = True
for f in self.filters:
if hasattr(f, 'filter'):
result = f.filter(record)
else:
result = f(record) # assume callable – will raise if not
if not result:
rv = False
break
return rv
def handle(self, record):
"""
Conditionally emit the specified logging record.
Emission depends on filters which may have been added to the handler.
Wrap the actual emission of the record with acquisition/release of
the I/O thread lock. Returns whether the filter passed the record for
emission.
"""
# 先对日志进行过滤处理再调用子类重写的emit方法执行真正的写入逻辑
rv = self.filter(record)
if rv:
self.acquire()
try:
self.emit(record)
finally:
self.release()
return rv
我们跟踪完了整个logging.info背后的流程,下面我们结合上面的代码以及官方的Logging Flow来梳理logging的流程框架
1.2 Logging 流程框架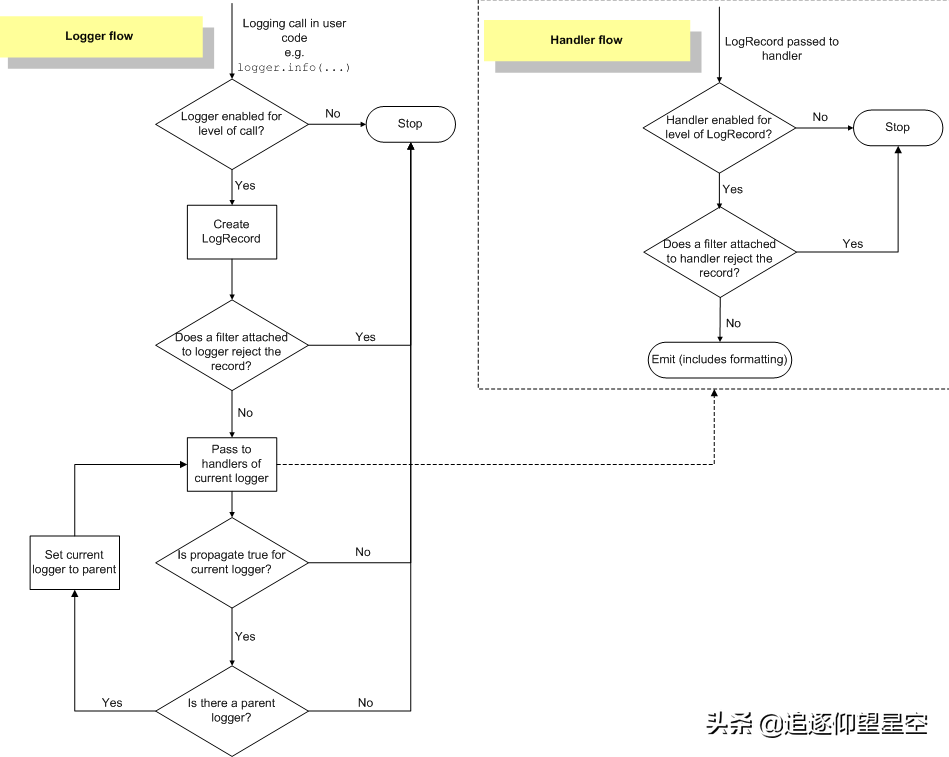
源码在 python 自己的 lib/logging/ 下,主要内容都在 __init__.py 里,根据流程图以及我们之前分析的源码来理解下面四个组件以及日志结构体的定义
Logger,核心组件,可以挂载若干个 Handler以及若干个 Filter,定义要响应的命名空间和日志级别Handler,可以挂载一个 Formatter和若干个 Filter,定义了要响应日志级别和输出方式Filter,虽然是过滤器,负责对输入的 LogRecord 做判断,返回 True/False 来决定挂载的 Logger 或 Handler 是否要处理当前日志,但是也可以拿来当做中间件来使用,可以自定义规则来改写LogRecord,继续传递给后续的Filter/Handler/LoggerFormatter,最终日志的格式化组件LogRecord,单条日志的结构体
根据流程图来看,主流程如下
日志打印请求到Logger后,第一判断当前Logger是否要处理这个级别,不处理的直接舍弃(第一层级别控制)生成一条LogRecord,会把包括调用来源等信息都一起打包好,依次调用Logger挂载的Filter链来处理一旦有Filter类的检测结果返回是False,则丢弃日志否则传给Logger挂载的Handler链中依次处理(进入Handler流程)如果开启了propagate属性,也就是“向上传播”,会将当前的LogRecord 传递给父类的Logger来进行处理,直接从第4步开始执行(不会触发第一层级别控制)
Handler流程
判当前Handler 是否要处理这个级别,不处理的直接舍弃(第二层级别控制)将收到的LogRecord 依次调用Handler挂载的Filter链来处理同理,调用Formatter2. 多进程场景下的Logging2.1 多进程场景Logging问题分析
Logging模块是线程安全的,我们在之前的代码中可以看到很多处使用到了threading.RLock(),特别是在调用info/error等方法打印日志时,最终都会调用顶级父类的handle方法,也就是
# logging/__init__.py
def handle(self, record):
# 先对日志进行过滤处理再调用子类重写的emit方法执行真正的写入逻辑
rv = self.filter(record)
if rv:
self.acquire()
try:
self.emit(record)
finally:
self.release()
return rv
这使得在多线程环境下可以保证同一时间只有一个线程可以调用handle方法进行写入
然而,另一个可能被忽视的场景是在多进程环境下引发的种种问题,我们在部署Python Web项目时,通常会以多进程的方式来启动,这就可能导致以下的几种问题:
日志紊乱:比如两个进程分别输出xxxx和yyyy两条日志,那么在文件中可能会得到类似xxyxyxyy这样的结果日志丢失:虽然读写日志是使用O_APPEND模式,保证了写文件的一致性,但是由于buffer的存在(数据先写入buffer,再触发flush机制刷入磁盘),fwrite的**作并不是多进程安全的日志丢失的另一种情况:使用RotatingFileHandler或者是TimerRotatingFileHandler的时候,在切换文件的时候会导致进程拿到的文件句柄不同,导致新文件被重复创建、数据写入旧文件2.2 多进程场景Logging解决方案
为了应对上述可能出现的情况,以下列举几种解决方案:
2.2.1 concurrent-log-handler模块(文件锁模式)# concurrent_log_handler/__init__.[y]
# 继承自logging的BaseRotatingHandler
class ConcurrentRotatingFileHandler(BaseRotatingHandler):
# 具体写入逻辑
def emit(self, record):
try:
msg = self.format(record)
# 加锁逻辑
try:
self._do_lock()
# 常规**作shouldRollover、doRollover做文件切分
try:
if self.shouldRollover(record):
self.doRollover()
except Exception as e:
self._console_log("Unable to do rollover: %s" % (e,), stack=True)
# Continue on anyway
self.do_write(msg)
finally:
self._do_unlock()
except (KeyboardInterrupt, SystemExit):
raise
except Exception:
self.handleError(record)
def _do_lock(self):
# 判断是否已被锁
if self.is_locked:
return # already locked… recursive?
# 触发文件锁
self._open_lockfile()
if self.stream_lock:
for i in range(10):
# noinspection PyBroadException
try:
# 调用portalocker lock的方法
lock(self.stream_lock, LOCK_EX)
self.is_locked = True
break
except Exception:
continue
else:
raise RuntimeError("Cannot acquire lock after 10 attempts")
else:
self._console_log("No self.stream_lock to lock", stack=True)
def _open_lockfile(self):
"""
改变文件权限
"""
if self.stream_lock and not self.stream_lock.closed:
self._console_log("Lockfile already open in this process")
return
lock_file = self.lockFilename
self._console_log(
"concurrent-log-handler %s opening %s" % (hash(self), lock_file), stack=False)
with self._alter_umask():
self.stream_lock = open(lock_file, "wb", buffering=0)
self._do_chown_and_chmod(lock_file)
def _do_unlock(self):
if self.stream_lock:
if self.is_locked:
try:
unlock(self.stream_lock)
finally:
self.is_locked = False
self.stream_lock.close()
self.stream_lock = None
else:
self._console_log("No self.stream_lock to unlock", stack=True)
# portalocker/portalocker.py
def lock(file_: typing.IO, flags: constants.LockFlags):
if flags & constants.LockFlags.SHARED:
…
else:
if flags & constants.LockFlags.NON_BLOCKING:
mode = msvcrt.LK_NBLCK
else:
mode = msvcrt.LK_LOCK
# windows locks byte ranges, so make sure to lock from file start
try:
savepos = file_.tell()
if savepos:
# [ ] test exclusive lock fails on seek here
# [ ] test if shared lock passes this point
file_.seek(0)
# [x] check if 0 param locks entire file (not documented in
# Python)
# [x] fails with "IOError: [Errno 13] Permission denied",
# but -1 seems to do the trick
try:
msvcrt.locking(file_.fileno(), mode, lock_length)
except IOError as exc_value:
# [ ] be more specific here
raise exceptions.LockException(
exceptions.LockException.LOCK_FAILED,
exc_value.strerror,
fh=file_)
finally:
if savepos:
file_.seek(savepos)
except IOError as exc_value:
raise exceptions.LockException(
exceptions.LockException.LOCK_FAILED, exc_value.strerror,
fh=file_)
"""
调用C运行时的文件锁机制
msvcrt.locking(fd, mode, nbytes)
Lock part of a file based on file descriptor fd from the C runtime. Raises OSError on failure. The locked region of the file extends from the current file position for nbytes bytes, and may continue beyond the end of the file. mode must be one of the LK_* constants listed below. Multiple regions in a file may be locked at the same time, but may not overlap. Adjacent regions are not merged; they must be unlocked individually.
Raises an auditing event msvcrt.locking with arguments fd, mode, nbytes.
"""
归根到底,就是在emit方法触发时调用了文件锁机制,将多个进程并发调用强制限制为单进程顺序调用,确保了日志写入的准确,但是在效率方面,频繁的对文件修改权限、加锁以及锁抢占机制都会造成效率低下的问题。
2.2.2 针对日志切分场景的复写doRollover方法以及复写FileHandler类
当然,除了上述的文件加锁方式,我们也可以自定义重写TimeRotatingFileHandler类或者FileHandler类,加入简单的多进程加锁的逻辑,例如fcntl.flock
static PyObject *
fcntl_flock_impl(PyObject *module, int fd, int code)
/*[clinic end generated code: output=84059e2b37d2fc64 input=0bfc00f795953452]*/
{
int ret;
int async_err = 0;
if (PySys_Audit("fcntl.flock", "ii", fd, code) < 0) {
return NULL;
}
# 触发linux flock命令加锁
#ifdef HAVE_FLOCK
do {
Py_BEGIN_ALLOW_THREADS
ret = flock(fd, code);
Py_END_ALLOW_THREADS
} while (ret == -1 && errno == EINTR && !(async_err = PyErr_CheckSignals()));
#else
#ifndef LOCK_SH
#define LOCK_SH 1 /* shared lock */
#define LOCK_EX 2 /* exclusive lock */
#define LOCK_NB 4 /* don't block when locking */
#define LOCK_UN 8 /* unlock */
#endif
{
struct flock l;
if (code == LOCK_UN)
l.l_type = F_UNLCK;
else if (code & LOCK_SH)
l.l_type = F_RDLCK;
else if (code & LOCK_EX)
l.l_type = F_WRLCK;
else {
PyErr_SetString(PyExc_ValueError,
"unrecognized flock argument");
return NULL;
}
l.l_whence = l.l_start = l.l_len = 0;
do {
Py_BEGIN_ALLOW_THREADS
ret = fcntl(fd, (code & LOCK_NB) ? F_SETLK : F_SETLKW, &l);
Py_END_ALLOW_THREADS
} while (ret == -1 && errno == EINTR && !(async_err = PyErr_CheckSignals()));
}
#endif /* HAVE_FLOCK */
if (ret < 0) {
return !async_err ? PyErr_SetFromErrno(PyExc_OSError) : NULL;
}
Py_RETURN_NONE;
}2.2.3 Master/Worker日志收集(Socket/Queue模式)
这种方式也是被官方主推的方式
Although logging is thread-safe, and logging to a single file from multiple threads in a single process is supported, logging to a single file from multiple processes is not supported, because there is no standard way to serialize access to a single file across multiple processes in Python. If you need to log to a single file from multiple processes, one way of doing this is to have all the processes log to a SocketHandler, and have a separate process which implements a socket server which reads from the socket and logs to file.(如果你需要将多个进程中的日志记录至单个文件,有一个方案是让所有进程都将日志记录至一个 SocketHandler,第二用一个实现了套接字服务器的单独进程一边从套接字中读取一边将日志记录至文件) (If you prefer, you can dedicate one thread in one of the existing processes to perform this function.) This section documents this approach in more detail and includes a working socket receiver which can be used as a starting point for you to adapt in your own applications.
Alternatively, you can use a Queue and a QueueHandler to send all logging events to one of the processes in your multi-process application. (你也可以使用 Queue 和 QueueHandler 将所有的日志**发送至你的多进程应用的一个进程中。)The following example script demonstrates how you can do this; in the example a separate listener process listens for events sent by other processes and logs them according to its own logging configuration. Although the example only demonstrates one way of doing it (for example, you may want to use a listener thread rather than a separate listener process – the implementation would be **ogous) it does allow for completely different logging configurations for the listener and the other processes in your application, and can be used as the basis for code meeting your own specific requirements:
看看QueueHandler的案例
import logging
import logging.config
import logging.handlers
from multiprocessing import Process, Queue
import random
import threading
import time
def logger_thread(q):
"""
单独的日志记录线程
"""
while True:
record = q.get()
if record is None:
break
# 获取record实例中的logger
logger = logging.getLogger(record.name)
# 调用logger的handle方法处理
logger.handle(record)
def worker_process(q):
# 日志写入进程
qh = logging.handlers.QueueHandler(q)
root = logging.getLogger()
root.setLevel(logging.DEBUG)
# 绑定QueueHandler到logger
root.addHandler(qh)
levels = [logging.DEBUG, logging.INFO, logging.WARNING, logging.ERROR,
logging.CRITICAL]
loggers = ['foo', 'foo.bar', 'foo.bar.baz',
'spam', 'spam.ham', 'spam.ham.eggs']
for i in range(100):
lvl = random.choice(levels)
logger = logging.getLogger(random.choice(loggers))
logger.log(lvl, 'Message no. %d', i)
if __name__ == '__main__':
q = Queue()
# 省略一大推配置
workers = []
# 多进程写入日志到Queue
for i in range(5):
wp = Process(target=worker_process, name='worker %d' % (i + 1), args=(q,))
workers.append(wp)
wp.start()
logging.config.dictConfig(d)
# 启动子线程负责日志收集写入
lp = threading.Thread(target=logger_thread, args=(q,))
lp.start()
# At this point, the main process could do some useful work of its own
# Once it's done that, it can wait for the workers to terminate…
for wp in workers:
wp.join()
# And now tell the logging thread to finish up, too
q.put(None)
lp.join()
看看SocketHandler的案例
# 发送端
import logging, logging.handlers
rootLogger = logging.getLogger('')
rootLogger.setLevel(logging.DEBUG)
# 指定ip、端口
socketHandler = logging.handlers.SocketHandler('localhost',
logging.handlers.DEFAULT_TCP_LOGGING_PORT)
# don't bother with a formatter, since a socket handler sends the event as
# an unformatted pickle
rootLogger.addHandler(socketHandler)
# Now, we can log to the root logger, or any other logger. First the root…
logging.info('Jackdaws love my big sphinx of quartz.')
# Now, define a couple of other loggers which might represent areas in your
# application:
logger1 = logging.getLogger('myapp.area1')
logger2 = logging.getLogger('myapp.area2')
logger1.debug('Quick zephyrs blow, vexing daft Jim.')
logger1.info('How quickly daft jumping zebras vex.')
logger2.warning('Jail zesty vixen who grabbed pay from quack.')
logger2.error('The five boxing wizards jump quickly.')
# 接收端
import pickle
import logging
import logging.handlers
import socketserver
import struct
class LogRecordStreamHandler(socketserver.StreamRequestHandler):
"""Handler for a streaming logging request.
This basically logs the record using whatever logging policy is
configured locally.
"""
def handle(self):
"""
Handle multiple requests – each expected to be a 4-byte length,
followed by the LogRecord in pickle format. Logs the record
according to whatever policy is configured locally.
"""
while True:
# 接收数据的流程
chunk = self.connection.recv(4)
if len(chunk) < 4:
break
slen = struct.unpack('>L', chunk)[0]
chunk = self.connection.recv(slen)
while len(chunk) < slen:
chunk = chunk + self.connection.recv(slen – len(chunk))
obj = self.unPickle(chunk)
# 生成LodRecord实例,调用handleLogRecord处理
record = logging.makeLogRecord(obj)
self.handleLogRecord(record)
def unPickle(self, data):
return pickle.loads(data)
def handleLogRecord(self, record):
# if a name is specified, we use the named logger rather than the one
# implied by the record.
if self.server.logname is not None:
name = self.server.logname
else:
name = record.name
logger = logging.getLogger(name)
# N.B. EVERY record gets logged. This is because Logger.handle
# is normally called AFTER logger-level filtering. If you want
# to do filtering, do it at the client end to save wasting
# cycles and network bandwidth!
logger.handle(record)
class LogRecordSocketReceiver(socketserver.ThreadingTCPServer):
"""
Simple TCP socket-based logging receiver suitable for testing.
"""
allow_reuse_address = True
def __init__(self, host='localhost',
port=logging.handlers.DEFAULT_TCP_LOGGING_PORT,
handler=LogRecordStreamHandler):
socketserver.ThreadingTCPServer.__init__(self, (host, port), handler)
self.abort = 0
self.timeout = 1
self.logname = None
def serve_until_stopped(self):
import select
abort = 0
while not abort:
# select方法接收端口数据
rd, wr, ex = select.select([self.socket.fileno()],
[], [],
self.timeout)
if rd:
# 调用LogRecordStreamHandler的handle方法处理
self.handle_request()
abort = self.abort
def main():
logging.basicConfig(
format='%(relativeCreated)5d %(name)-15s %(levelname)-8s %(message)s')
tcpserver = LogRecordSocketReceiver()
print('About to start TCP server…')
tcpserver.serve_until_stopped()
if __name__ == '__main__':
main()
有关于 Master/Worker的方式就是上述的两种模式,日志写入的效率不受并发的影响,最终取决于写入线程。此外,对于日志的写入慢、阻塞问题,同样可以使用QueueHandlers以及其扩展的QueueListener来处理。
作者:技术拆解官原文链接:https://juejin.cn/post/6945301448934719518
拓展知识:
前沿拓展:
推荐学习22天试水Python社招,历经“百度+字节+天融”等6家 金三即过,这300道python高频面试都没刷,银四怎么闯?
前言
Logging日志记录框架是Python内置打印模块,它对很多Python开发者来说是既熟悉又陌生,确实,它使用起来很简单,只需要我们简单一行代码,就可以打印出日志
import logging
logging.debug("This is a debug log.")
logging.info("This is a info log.")
logging.warning("This is a warning log.")
logging.error("This is a error log.")
logging.critical("This is a critical log.")
# output
WARNING:root:This is a warning log.
ERROR:root:This is a error log.
CRITICAL:root:This is a critical log.
但是对于我们在实际项目中需要基于Logging来开发日志框架时,常常会遇到各种各样的问题,例如性能方面的多进程下滚动日志记录丢失、日志记录效率低的问题以及在二次开发时因为没有理解Logging内部流程导致没有利用到Logging的核心机制等等。
接下来,我们就从一行代码来深挖Logging System的秘密
1. 深入Logging模块源码1.1 logging.info做了什么?
logging.info作为大多数人使用logging模块的第一行代码,隐藏了很多实现细节,以至于我们在最初都只关注功能,而忽略了它的内部细节
import logging
logging.info("This is a info log.")
# logging/__init__.py
def info(msg, *args, **kwargs):
"""
Log a message with severity 'INFO' on the root logger. If the logger has
no handlers, call basicConfig() to add a console handler with a pre-defined
format.
"""
# 没有绑定handlers就调用basicConfig方法
if len(root.handlers) == 0:
basicConfig()
root.info(msg, *args, **kwargs)
_lock = threading.RLock()
def _acquireLock():
"""
Acquire the module-level lock for serializing access to shared data.
This should be released with _releaseLock().
"""
if _lock:
_lock.acquire()
def _releaseLock():
"""
Release the module-level lock acquired by calling _acquireLock().
"""
if _lock:
_lock.release()
def basicConfig(**kwargs):
"""
很方便的一步到位的配置方法创建一个StreamHandler打印日志到控制台
This function does nothing if the root logger already has handlers
configured. It is a convenience method intended for use by simple scripts
to do one-shot configuration of the logging package.
The default behaviour is to create a StreamHandler which writes to
sys.stderr, set a formatter using the BASIC_FORMAT format string, and
add the handler to the root logger.
"""
# Add thread safety in case someone mistakenly calls
# basicConfig() from multiple threads
# 为了确保多线程安全的写日志**作,做了加锁处理(如上,标准的多线程锁**作)
_acquireLock()
try:
if len(root.handlers) == 0:
# 对于handler的处理,有filename就新建FileHandler,没有就选择StreamHandler
handlers = kwargs.pop("handlers", None)
if handlers is None:
if "stream" in kwargs and "filename" in kwargs:
raise ValueError("'stream' and 'filename' should not be "
"specified together")
else:
if "stream" in kwargs or "filename" in kwargs:
raise ValueError("'stream' or 'filename' should not be "
"specified together with 'handlers'")
if handlers is None:
filename = kwargs.pop("filename", None)
mode = kwargs.pop("filemode", 'a')
if filename:
h = FileHandler(filename, mode)
else:
stream = kwargs.pop("stream", None)
h = StreamHandler(stream)
handlers = [h]
dfs = kwargs.pop("datefmt", None)
style = kwargs.pop("style", '%')
if style not in _STYLES:
raise ValueError('Style must be one of: %s' % ','.join(
_STYLES.keys()))
fs = kwargs.pop("format", _STYLES[style][1])
fmt = Formatter(fs, dfs, style)
# 绑定handler到root
for h in handlers:
if h.formatter is None:
h.setFormatter(fmt)
root.addHandler(h)
level = kwargs.pop("level", None)
if level is not None:
root.setLevel(level)
if kwargs:
keys = ', '.join(kwargs.keys())
raise ValueError('Unrecognised argument(s): %s' % keys)
finally:
_releaseLock()
到目前为止,可以看到logging.info通过调用basicConfig()来完成初始化handler之后才开始正式打印,而basicConfig()的逻辑是通过多线程锁状态下的一个初始化handler->绑定root的**作,那这个root代表了什么呢?
# logging/__init__.py
root = RootLogger(WARNING)
Logger.root = root
Logger.manager = Manager(Logger.root)
class RootLogger(Logger):
"""
A root logger is not that different to any other logger, except that
it must have a logging level and there is only one instance of it in
the hierarchy.
"""
def __init__(self, level):
"""
Initialize the logger with the name "root".
"""
# 调用父类的初始化,传入了root和WARNING两个参数,所以我们直接调用logging.info时是不能输出任何信息的,因为logger level初始化时就被指定成了WARNING
Logger.__init__(self, "root", level)
def __reduce__(self):
return getLogger, ()
class Logger(Filterer):
"""
Instances of the Logger class represent a single logging channel. A
"logging channel" indicates an area of an application. Exactly how an
"area" is defined is up to the application developer. Since an
application can have any number of areas, logging channels are identified
by a unique string. Application areas can be nested (e.g. an area
of "input processing" might include sub-areas "read CSV files", "read
XLS files" and "read Gnumeric files"). To cater for this natural nesting,
channel names are organized into a namespace hierarchy where levels are
separated by periods, much like the Java or Python package namespace. So
in the instance given above, channel names might be "input" for the upper
level, and "input.csv", "input.xls" and "input.gnu" for the sub-levels.
There is no arbitrary limit to the depth of nesting.
"""
def __init__(self, name, level=NOTSET):
"""
Initialize the logger with a name and an optional level.
"""
Filterer.__init__(self)
self.name = name # 指定name,也就是之前的root
self.level = _checkLevel(level) # 指定logger level
self.parent = None
self.propagate = True
self.handlers = []
self.disabled = False
self._cache = {}
def info(self, msg, *args, **kwargs):
"""
Log 'msg % args' with severity 'INFO'.
To pass exception information, use the keyword argument exc_info with
a true value, e.g.
logger.info("Houston, we have a %s", "interesting problem", exc_info=1)
"""
# 这步判断是为了判断是否该logger level可以被输出
if self.isEnabledFor(INFO):
self._log(INFO, msg, args, **kwargs)
def getEffectiveLevel(self):
"""
Get the effective level for this logger.
Loop through this logger and its parents in the logger hierarchy,
looking for a non-zero logging level. Return the first one found.
"""
# 寻找父级logger level
logger = self
while logger:
if logger.level:
return logger.level
logger = logger.parent
return NOTSET
def isEnabledFor(self, level):
"""
Is this logger enabled for level 'level'?
"""
try:
return self._cache[level]
except KeyError:
# 又出现的加锁**作
_acquireLock()
if self.manager.disable >= level:
is_enabled = self._cache[level] = False
else:
is_enabled = self._cache[level] = level >= self.getEffectiveLevel()
_releaseLock()
return is_enabled
root是RootLogger的实例,RootLogger继承于Logger,通过_log来统一记录日志,而在_log之前会有个logger level的判断
# 用来获取堆栈中的第一个调用者
# _srcfile is used when walking the stack to check when we've got the first
# caller stack frame, by skipping frames whose filename is that of this
# module's source. It therefore should contain the filename of this module's
# source file.
#
# Ordinarily we would use __file__ for this, but frozen modules don't always
# have __file__ set, for some reason (see Issue #21736). Thus, we get the
# filename from a handy code object from a function defined in this module.
# (There's no particular reason for picking addLevelName.)
#
_srcfile = os.path.normcase(addLevelName.__code__.co_filename)
# _srcfile is only used in conjunction with sys._getframe().
# To provide compatibility with older versions of Python, set _srcfile
# to None if _getframe() is not available; this value will prevent
# findCaller() from being called. You can also do this if you want to avoid
# the overhead of fetching caller information, even when _getframe() is
# available.
#if not hasattr(sys, '_getframe'):
# _srcfile = None
def _log(self, level, msg, args, exc_info=None, extra=None, stack_info=False):
"""
Low-level logging routine which creates a LogRecord and then calls
all the handlers of this logger to handle the record.
"""
sinfo = None
if _srcfile:
#IronPython doesn't track Python frames, so findCaller raises an
#exception on some versions of IronPython. We trap it here so that
#IronPython can use logging.
try:
fn, lno, func, sinfo = self.findCaller(stack_info)
except ValueError: # pragma: no cover
fn, lno, func = "(unknown file)", 0, "(unknown function)"
else: # pragma: no cover
fn, lno, func = "(unknown file)", 0, "(unknown function)"
if exc_info:
if isinstance(exc_info, BaseException):
exc_info = (type(exc_info), exc_info, exc_info.__traceback__)
elif not isinstance(exc_info, tuple):
exc_info = sys.exc_info()
# 通过makeRecord生成一条日志记录
record = self.makeRecord(self.name, level, fn, lno, msg, args,
exc_info, func, extra, sinfo)
# 处理
self.handle(record)
def findCaller(self, stack_info=False):
"""
通过调用堆栈获取文件名、行数和调用者
Find the stack frame of the caller so that we can note the source
file name, line number and function name.
"""
f = currentframe()
#On some versions of IronPython, currentframe() returns None if
#IronPython isn't run with -X:Frames.
if f is not None:
f = f.f_back
rv = "(unknown file)", 0, "(unknown function)", None
while hasattr(f, "f_code"):
co = f.f_code
filename = os.path.normcase(co.co_filename)
if filename == _srcfile:
f = f.f_back
continue
sinfo = None
if stack_info:
sio = io.StringIO()
sio.write('Stack (most recent call last):n')
traceback.print_stack(f, file=sio)
sinfo = sio.getvalue()
if sinfo[-1] == 'n':
sinfo = sinfo[:-1]
sio.close()
rv = (co.co_filename, f.f_lineno, co.co_name, sinfo)
break
return rv
def makeRecord(self, name, level, fn, lno, msg, args, exc_info,
func=None, extra=None, sinfo=None):
"""
A factory method which can be overridden in subclasses to create
specialized LogRecords.
"""
# 生成_logRecordFactory的实例
rv = _logRecordFactory(name, level, fn, lno, msg, args, exc_info, func,
sinfo)
if extra is not None:
for key in extra:
if (key in ["message", "asctime"]) or (key in rv.__dict__):
raise KeyError("Attempt to overwrite %r in LogRecord" % key)
rv.__dict__[key] = extra[key]
return rv
def handle(self, record):
"""
Call the handlers for the specified record.
This method is used for unpickled records received from a socket, as
well as those created locally. Logger-level filtering is applied.
"""
if (not self.disabled) and self.filter(record):
self.callHandlers(record)
def callHandlers(self, record):
"""
Pass a record to all relevant handlers.
Loop through all handlers for this logger and its parents in the
logger hierarchy. If no handler was found, output a one-off error
message to sys.stderr. Stop searching up the hierarchy whenever a
logger with the "propagate" attribute set to zero is found – that
will be the last logger whose handlers are called.
"""
c = self
found = 0
# 轮询自身绑定的handlers,并调用handle方法来处理该record实例,这里有点类似于import的流程,调用sys.meta_path的importer来处理path,也是同样的道理,这里我们回忆之前的rootLogger,我们调用baseConfig来初始化使FileHandler绑定到root,第二调用root.info,最终就来到了这个方法,调用到了FileHandler.handle方法来处理
while c:
for hdlr in c.handlers:
found = found + 1
if record.levelno >= hdlr.level:
hdlr.handle(record)
if not c.propagate:
c = None #break out
else:
c = c.parent
if (found == 0):
if lastResort:
if record.levelno >= lastResort.level:
lastResort.handle(record)
elif raiseExceptions and not self.manager.emittedNoHandlerWarning:
sys.stderr.write("No handlers could be found for logger"
" "%s"n" % self.name)
self.manager.emittedNoHandlerWarning = True
继续来看FileHandler
class FileHandler(StreamHandler):
def _open(self):
"""
Open the current base file with the (original) mode and encoding.
Return the resulting stream.
"""
return open(self.baseFilename, self.mode, encoding=self.encoding)
def emit(self, record):
"""
Emit a record.
If the stream was not opened because 'delay' was specified in the
constructor, open it before calling the superclass's emit.
"""
# 打开文件句柄(文件流)
if self.stream is None:
self.stream = self._open()
# 调用StreamHandler的emit方法
StreamHandler.emit(self, record)
class StreamHandler(Handler):
def flush(self):
"""
Flushes the stream.
"""
# 同样时加锁刷入
self.acquire()
try:
if self.stream and hasattr(self.stream, "flush"):
self.stream.flush()
finally:
self.release()
def emit(self, record):
"""
Emit a record.
If a formatter is specified, it is used to format the record.
The record is then written to the stream with a trailing newline. If
exception information is present, it is formatted using
traceback.print_exception and appended to the stream. If the stream
has an 'encoding' attribute, it is used to determine how to do the
output to the stream.
"""
try:
msg = self.format(record)
stream = self.stream
# issue 35046: merged two stream.writes into one.
# 写入流的缓冲区,执行flush
stream.write(msg + self.terminator)
self.flush()
except RecursionError: # See issue 36272
raise
except Exception:
self.handleError(record)
class Handler(Filterer):
# FileHandler的handle方法来源于祖父辈的Handler
def filter(self, record):
"""
Determine if a record is loggable by consulting all the filters.
The default is to allow the record to be logged; any filter can veto
this and the record is then dropped. Returns a zero value if a record
is to be dropped, else non-zero.
.. versionchanged:: 3.2
Allow filters to be just callables.
"""
rv = True
for f in self.filters:
if hasattr(f, 'filter'):
result = f.filter(record)
else:
result = f(record) # assume callable – will raise if not
if not result:
rv = False
break
return rv
def handle(self, record):
"""
Conditionally emit the specified logging record.
Emission depends on filters which may have been added to the handler.
Wrap the actual emission of the record with acquisition/release of
the I/O thread lock. Returns whether the filter passed the record for
emission.
"""
# 先对日志进行过滤处理再调用子类重写的emit方法执行真正的写入逻辑
rv = self.filter(record)
if rv:
self.acquire()
try:
self.emit(record)
finally:
self.release()
return rv
我们跟踪完了整个logging.info背后的流程,下面我们结合上面的代码以及官方的Logging Flow来梳理logging的流程框架
1.2 Logging 流程框架
源码在 python 自己的 lib/logging/ 下,主要内容都在 __init__.py 里,根据流程图以及我们之前分析的源码来理解下面四个组件以及日志结构体的定义
Logger,核心组件,可以挂载若干个 Handler以及若干个 Filter,定义要响应的命名空间和日志级别Handler,可以挂载一个 Formatter和若干个 Filter,定义了要响应日志级别和输出方式Filter,虽然是过滤器,负责对输入的 LogRecord 做判断,返回 True/False 来决定挂载的 Logger 或 Handler 是否要处理当前日志,但是也可以拿来当做中间件来使用,可以自定义规则来改写LogRecord,继续传递给后续的Filter/Handler/LoggerFormatter,最终日志的格式化组件LogRecord,单条日志的结构体
根据流程图来看,主流程如下
日志打印请求到Logger后,第一判断当前Logger是否要处理这个级别,不处理的直接舍弃(第一层级别控制)生成一条LogRecord,会把包括调用来源等信息都一起打包好,依次调用Logger挂载的Filter链来处理一旦有Filter类的检测结果返回是False,则丢弃日志否则传给Logger挂载的Handler链中依次处理(进入Handler流程)如果开启了propagate属性,也就是“向上传播”,会将当前的LogRecord 传递给父类的Logger来进行处理,直接从第4步开始执行(不会触发第一层级别控制)
Handler流程
判当前Handler 是否要处理这个级别,不处理的直接舍弃(第二层级别控制)将收到的LogRecord 依次调用Handler挂载的Filter链来处理同理,调用Formatter2. 多进程场景下的Logging2.1 多进程场景Logging问题分析
Logging模块是线程安全的,我们在之前的代码中可以看到很多处使用到了threading.RLock(),特别是在调用info/error等方法打印日志时,最终都会调用顶级父类的handle方法,也就是
# logging/__init__.py
def handle(self, record):
# 先对日志进行过滤处理再调用子类重写的emit方法执行真正的写入逻辑
rv = self.filter(record)
if rv:
self.acquire()
try:
self.emit(record)
finally:
self.release()
return rv
这使得在多线程环境下可以保证同一时间只有一个线程可以调用handle方法进行写入
然而,另一个可能被忽视的场景是在多进程环境下引发的种种问题,我们在部署Python Web项目时,通常会以多进程的方式来启动,这就可能导致以下的几种问题:
日志紊乱:比如两个进程分别输出xxxx和yyyy两条日志,那么在文件中可能会得到类似xxyxyxyy这样的结果日志丢失:虽然读写日志是使用O_APPEND模式,保证了写文件的一致性,但是由于buffer的存在(数据先写入buffer,再触发flush机制刷入磁盘),fwrite的**作并不是多进程安全的日志丢失的另一种情况:使用RotatingFileHandler或者是TimerRotatingFileHandler的时候,在切换文件的时候会导致进程拿到的文件句柄不同,导致新文件被重复创建、数据写入旧文件2.2 多进程场景Logging解决方案
为了应对上述可能出现的情况,以下列举几种解决方案:
2.2.1 concurrent-log-handler模块(文件锁模式)# concurrent_log_handler/__init__.[y]
# 继承自logging的BaseRotatingHandler
class ConcurrentRotatingFileHandler(BaseRotatingHandler):
# 具体写入逻辑
def emit(self, record):
try:
msg = self.format(record)
# 加锁逻辑
try:
self._do_lock()
# 常规**作shouldRollover、doRollover做文件切分
try:
if self.shouldRollover(record):
self.doRollover()
except Exception as e:
self._console_log("Unable to do rollover: %s" % (e,), stack=True)
# Continue on anyway
self.do_write(msg)
finally:
self._do_unlock()
except (KeyboardInterrupt, SystemExit):
raise
except Exception:
self.handleError(record)
def _do_lock(self):
# 判断是否已被锁
if self.is_locked:
return # already locked… recursive?
# 触发文件锁
self._open_lockfile()
if self.stream_lock:
for i in range(10):
# noinspection PyBroadException
try:
# 调用portalocker lock的方法
lock(self.stream_lock, LOCK_EX)
self.is_locked = True
break
except Exception:
continue
else:
raise RuntimeError("Cannot acquire lock after 10 attempts")
else:
self._console_log("No self.stream_lock to lock", stack=True)
def _open_lockfile(self):
"""
改变文件权限
"""
if self.stream_lock and not self.stream_lock.closed:
self._console_log("Lockfile already open in this process")
return
lock_file = self.lockFilename
self._console_log(
"concurrent-log-handler %s opening %s" % (hash(self), lock_file), stack=False)
with self._alter_umask():
self.stream_lock = open(lock_file, "wb", buffering=0)
self._do_chown_and_chmod(lock_file)
def _do_unlock(self):
if self.stream_lock:
if self.is_locked:
try:
unlock(self.stream_lock)
finally:
self.is_locked = False
self.stream_lock.close()
self.stream_lock = None
else:
self._console_log("No self.stream_lock to unlock", stack=True)
# portalocker/portalocker.py
def lock(file_: typing.IO, flags: constants.LockFlags):
if flags & constants.LockFlags.SHARED:
…
else:
if flags & constants.LockFlags.NON_BLOCKING:
mode = msvcrt.LK_NBLCK
else:
mode = msvcrt.LK_LOCK
# windows locks byte ranges, so make sure to lock from file start
try:
savepos = file_.tell()
if savepos:
# [ ] test exclusive lock fails on seek here
# [ ] test if shared lock passes this point
file_.seek(0)
# [x] check if 0 param locks entire file (not documented in
# Python)
# [x] fails with "IOError: [Errno 13] Permission denied",
# but -1 seems to do the trick
try:
msvcrt.locking(file_.fileno(), mode, lock_length)
except IOError as exc_value:
# [ ] be more specific here
raise exceptions.LockException(
exceptions.LockException.LOCK_FAILED,
exc_value.strerror,
fh=file_)
finally:
if savepos:
file_.seek(savepos)
except IOError as exc_value:
raise exceptions.LockException(
exceptions.LockException.LOCK_FAILED, exc_value.strerror,
fh=file_)
"""
调用C运行时的文件锁机制
msvcrt.locking(fd, mode, nbytes)
Lock part of a file based on file descriptor fd from the C runtime. Raises OSError on failure. The locked region of the file extends from the current file position for nbytes bytes, and may continue beyond the end of the file. mode must be one of the LK_* constants listed below. Multiple regions in a file may be locked at the same time, but may not overlap. Adjacent regions are not merged; they must be unlocked individually.
Raises an auditing event msvcrt.locking with arguments fd, mode, nbytes.
"""
归根到底,就是在emit方法触发时调用了文件锁机制,将多个进程并发调用强制限制为单进程顺序调用,确保了日志写入的准确,但是在效率方面,频繁的对文件修改权限、加锁以及锁抢占机制都会造成效率低下的问题。
2.2.2 针对日志切分场景的复写doRollover方法以及复写FileHandler类
当然,除了上述的文件加锁方式,我们也可以自定义重写TimeRotatingFileHandler类或者FileHandler类,加入简单的多进程加锁的逻辑,例如fcntl.flock
static PyObject *
fcntl_flock_impl(PyObject *module, int fd, int code)
/*[clinic end generated code: output=84059e2b37d2fc64 input=0bfc00f795953452]*/
{
int ret;
int async_err = 0;
if (PySys_Audit("fcntl.flock", "ii", fd, code) < 0) {
return NULL;
}
# 触发linux flock命令加锁
#ifdef HAVE_FLOCK
do {
Py_BEGIN_ALLOW_THREADS
ret = flock(fd, code);
Py_END_ALLOW_THREADS
} while (ret == -1 && errno == EINTR && !(async_err = PyErr_CheckSignals()));
#else
#ifndef LOCK_SH
#define LOCK_SH 1 /* shared lock */
#define LOCK_EX 2 /* exclusive lock */
#define LOCK_NB 4 /* don't block when locking */
#define LOCK_UN 8 /* unlock */
#endif
{
struct flock l;
if (code == LOCK_UN)
l.l_type = F_UNLCK;
else if (code & LOCK_SH)
l.l_type = F_RDLCK;
else if (code & LOCK_EX)
l.l_type = F_WRLCK;
else {
PyErr_SetString(PyExc_ValueError,
"unrecognized flock argument");
return NULL;
}
l.l_whence = l.l_start = l.l_len = 0;
do {
Py_BEGIN_ALLOW_THREADS
ret = fcntl(fd, (code & LOCK_NB) ? F_SETLK : F_SETLKW, &l);
Py_END_ALLOW_THREADS
} while (ret == -1 && errno == EINTR && !(async_err = PyErr_CheckSignals()));
}
#endif /* HAVE_FLOCK */
if (ret < 0) {
return !async_err ? PyErr_SetFromErrno(PyExc_OSError) : NULL;
}
Py_RETURN_NONE;
}2.2.3 Master/Worker日志收集(Socket/Queue模式)
这种方式也是被官方主推的方式
Although logging is thread-safe, and logging to a single file from multiple threads in a single process is supported, logging to a single file from multiple processes is not supported, because there is no standard way to serialize access to a single file across multiple processes in Python. If you need to log to a single file from multiple processes, one way of doing this is to have all the processes log to a SocketHandler, and have a separate process which implements a socket server which reads from the socket and logs to file.(如果你需要将多个进程中的日志记录至单个文件,有一个方案是让所有进程都将日志记录至一个 SocketHandler,第二用一个实现了套接字服务器的单独进程一边从套接字中读取一边将日志记录至文件) (If you prefer, you can dedicate one thread in one of the existing processes to perform this function.) This section documents this approach in more detail and includes a working socket receiver which can be used as a starting point for you to adapt in your own applications.
Alternatively, you can use a Queue and a QueueHandler to send all logging events to one of the processes in your multi-process application. (你也可以使用 Queue 和 QueueHandler 将所有的日志**发送至你的多进程应用的一个进程中。)The following example script demonstrates how you can do this; in the example a separate listener process listens for events sent by other processes and logs them according to its own logging configuration. Although the example only demonstrates one way of doing it (for example, you may want to use a listener thread rather than a separate listener process – the implementation would be **ogous) it does allow for completely different logging configurations for the listener and the other processes in your application, and can be used as the basis for code meeting your own specific requirements:
看看QueueHandler的案例
import logging
import logging.config
import logging.handlers
from multiprocessing import Process, Queue
import random
import threading
import time
def logger_thread(q):
"""
单独的日志记录线程
"""
while True:
record = q.get()
if record is None:
break
# 获取record实例中的logger
logger = logging.getLogger(record.name)
# 调用logger的handle方法处理
logger.handle(record)
def worker_process(q):
# 日志写入进程
qh = logging.handlers.QueueHandler(q)
root = logging.getLogger()
root.setLevel(logging.DEBUG)
# 绑定QueueHandler到logger
root.addHandler(qh)
levels = [logging.DEBUG, logging.INFO, logging.WARNING, logging.ERROR,
logging.CRITICAL]
loggers = ['foo', 'foo.bar', 'foo.bar.baz',
'spam', 'spam.ham', 'spam.ham.eggs']
for i in range(100):
lvl = random.choice(levels)
logger = logging.getLogger(random.choice(loggers))
logger.log(lvl, 'Message no. %d', i)
if __name__ == '__main__':
q = Queue()
# 省略一大推配置
workers = []
# 多进程写入日志到Queue
for i in range(5):
wp = Process(target=worker_process, name='worker %d' % (i + 1), args=(q,))
workers.append(wp)
wp.start()
logging.config.dictConfig(d)
# 启动子线程负责日志收集写入
lp = threading.Thread(target=logger_thread, args=(q,))
lp.start()
# At this point, the main process could do some useful work of its own
# Once it's done that, it can wait for the workers to terminate…
for wp in workers:
wp.join()
# And now tell the logging thread to finish up, too
q.put(None)
lp.join()
看看SocketHandler的案例
# 发送端
import logging, logging.handlers
rootLogger = logging.getLogger('')
rootLogger.setLevel(logging.DEBUG)
# 指定ip、端口
socketHandler = logging.handlers.SocketHandler('localhost',
logging.handlers.DEFAULT_TCP_LOGGING_PORT)
# don't bother with a formatter, since a socket handler sends the event as
# an unformatted pickle
rootLogger.addHandler(socketHandler)
# Now, we can log to the root logger, or any other logger. First the root…
logging.info('Jackdaws love my big sphinx of quartz.')
# Now, define a couple of other loggers which might represent areas in your
# application:
logger1 = logging.getLogger('myapp.area1')
logger2 = logging.getLogger('myapp.area2')
logger1.debug('Quick zephyrs blow, vexing daft Jim.')
logger1.info('How quickly daft jumping zebras vex.')
logger2.warning('Jail zesty vixen who grabbed pay from quack.')
logger2.error('The five boxing wizards jump quickly.')
# 接收端
import pickle
import logging
import logging.handlers
import socketserver
import struct
class LogRecordStreamHandler(socketserver.StreamRequestHandler):
"""Handler for a streaming logging request.
This basically logs the record using whatever logging policy is
configured locally.
"""
def handle(self):
"""
Handle multiple requests – each expected to be a 4-byte length,
followed by the LogRecord in pickle format. Logs the record
according to whatever policy is configured locally.
"""
while True:
# 接收数据的流程
chunk = self.connection.recv(4)
if len(chunk) < 4:
break
slen = struct.unpack('>L', chunk)[0]
chunk = self.connection.recv(slen)
while len(chunk) < slen:
chunk = chunk + self.connection.recv(slen – len(chunk))
obj = self.unPickle(chunk)
# 生成LodRecord实例,调用handleLogRecord处理
record = logging.makeLogRecord(obj)
self.handleLogRecord(record)
def unPickle(self, data):
return pickle.loads(data)
def handleLogRecord(self, record):
# if a name is specified, we use the named logger rather than the one
# implied by the record.
if self.server.logname is not None:
name = self.server.logname
else:
name = record.name
logger = logging.getLogger(name)
# N.B. EVERY record gets logged. This is because Logger.handle
# is normally called AFTER logger-level filtering. If you want
# to do filtering, do it at the client end to save wasting
# cycles and network bandwidth!
logger.handle(record)
class LogRecordSocketReceiver(socketserver.ThreadingTCPServer):
"""
Simple TCP socket-based logging receiver suitable for testing.
"""
allow_reuse_address = True
def __init__(self, host='localhost',
port=logging.handlers.DEFAULT_TCP_LOGGING_PORT,
handler=LogRecordStreamHandler):
socketserver.ThreadingTCPServer.__init__(self, (host, port), handler)
self.abort = 0
self.timeout = 1
self.logname = None
def serve_until_stopped(self):
import select
abort = 0
while not abort:
# select方法接收端口数据
rd, wr, ex = select.select([self.socket.fileno()],
[], [],
self.timeout)
if rd:
# 调用LogRecordStreamHandler的handle方法处理
self.handle_request()
abort = self.abort
def main():
logging.basicConfig(
format='%(relativeCreated)5d %(name)-15s %(levelname)-8s %(message)s')
tcpserver = LogRecordSocketReceiver()
print('About to start TCP server…')
tcpserver.serve_until_stopped()
if __name__ == '__main__':
main()
有关于 Master/Worker的方式就是上述的两种模式,日志写入的效率不受并发的影响,最终取决于写入线程。此外,对于日志的写入慢、阻塞问题,同样可以使用QueueHandlers以及其扩展的QueueListener来处理。
作者:技术拆解官原文链接:https://juejin.cn/post/6945301448934719518
拓展知识:
前沿拓展:
推荐学习22天试水Python社招,历经“百度+字节+天融”等6家 金三即过,这300道python高频面试都没刷,银四怎么闯?
前言
Logging日志记录框架是Python内置打印模块,它对很多Python开发者来说是既熟悉又陌生,确实,它使用起来很简单,只需要我们简单一行代码,就可以打印出日志
import logging
logging.debug("This is a debug log.")
logging.info("This is a info log.")
logging.warning("This is a warning log.")
logging.error("This is a error log.")
logging.critical("This is a critical log.")
# output
WARNING:root:This is a warning log.
ERROR:root:This is a error log.
CRITICAL:root:This is a critical log.
但是对于我们在实际项目中需要基于Logging来开发日志框架时,常常会遇到各种各样的问题,例如性能方面的多进程下滚动日志记录丢失、日志记录效率低的问题以及在二次开发时因为没有理解Logging内部流程导致没有利用到Logging的核心机制等等。
接下来,我们就从一行代码来深挖Logging System的秘密
1. 深入Logging模块源码1.1 logging.info做了什么?
logging.info作为大多数人使用logging模块的第一行代码,隐藏了很多实现细节,以至于我们在最初都只关注功能,而忽略了它的内部细节
import logging
logging.info("This is a info log.")
# logging/__init__.py
def info(msg, *args, **kwargs):
"""
Log a message with severity 'INFO' on the root logger. If the logger has
no handlers, call basicConfig() to add a console handler with a pre-defined
format.
"""
# 没有绑定handlers就调用basicConfig方法
if len(root.handlers) == 0:
basicConfig()
root.info(msg, *args, **kwargs)
_lock = threading.RLock()
def _acquireLock():
"""
Acquire the module-level lock for serializing access to shared data.
This should be released with _releaseLock().
"""
if _lock:
_lock.acquire()
def _releaseLock():
"""
Release the module-level lock acquired by calling _acquireLock().
"""
if _lock:
_lock.release()
def basicConfig(**kwargs):
"""
很方便的一步到位的配置方法创建一个StreamHandler打印日志到控制台
This function does nothing if the root logger already has handlers
configured. It is a convenience method intended for use by simple scripts
to do one-shot configuration of the logging package.
The default behaviour is to create a StreamHandler which writes to
sys.stderr, set a formatter using the BASIC_FORMAT format string, and
add the handler to the root logger.
"""
# Add thread safety in case someone mistakenly calls
# basicConfig() from multiple threads
# 为了确保多线程安全的写日志**作,做了加锁处理(如上,标准的多线程锁**作)
_acquireLock()
try:
if len(root.handlers) == 0:
# 对于handler的处理,有filename就新建FileHandler,没有就选择StreamHandler
handlers = kwargs.pop("handlers", None)
if handlers is None:
if "stream" in kwargs and "filename" in kwargs:
raise ValueError("'stream' and 'filename' should not be "
"specified together")
else:
if "stream" in kwargs or "filename" in kwargs:
raise ValueError("'stream' or 'filename' should not be "
"specified together with 'handlers'")
if handlers is None:
filename = kwargs.pop("filename", None)
mode = kwargs.pop("filemode", 'a')
if filename:
h = FileHandler(filename, mode)
else:
stream = kwargs.pop("stream", None)
h = StreamHandler(stream)
handlers = [h]
dfs = kwargs.pop("datefmt", None)
style = kwargs.pop("style", '%')
if style not in _STYLES:
raise ValueError('Style must be one of: %s' % ','.join(
_STYLES.keys()))
fs = kwargs.pop("format", _STYLES[style][1])
fmt = Formatter(fs, dfs, style)
# 绑定handler到root
for h in handlers:
if h.formatter is None:
h.setFormatter(fmt)
root.addHandler(h)
level = kwargs.pop("level", None)
if level is not None:
root.setLevel(level)
if kwargs:
keys = ', '.join(kwargs.keys())
raise ValueError('Unrecognised argument(s): %s' % keys)
finally:
_releaseLock()
到目前为止,可以看到logging.info通过调用basicConfig()来完成初始化handler之后才开始正式打印,而basicConfig()的逻辑是通过多线程锁状态下的一个初始化handler->绑定root的**作,那这个root代表了什么呢?
# logging/__init__.py
root = RootLogger(WARNING)
Logger.root = root
Logger.manager = Manager(Logger.root)
class RootLogger(Logger):
"""
A root logger is not that different to any other logger, except that
it must have a logging level and there is only one instance of it in
the hierarchy.
"""
def __init__(self, level):
"""
Initialize the logger with the name "root".
"""
# 调用父类的初始化,传入了root和WARNING两个参数,所以我们直接调用logging.info时是不能输出任何信息的,因为logger level初始化时就被指定成了WARNING
Logger.__init__(self, "root", level)
def __reduce__(self):
return getLogger, ()
class Logger(Filterer):
"""
Instances of the Logger class represent a single logging channel. A
"logging channel" indicates an area of an application. Exactly how an
"area" is defined is up to the application developer. Since an
application can have any number of areas, logging channels are identified
by a unique string. Application areas can be nested (e.g. an area
of "input processing" might include sub-areas "read CSV files", "read
XLS files" and "read Gnumeric files"). To cater for this natural nesting,
channel names are organized into a namespace hierarchy where levels are
separated by periods, much like the Java or Python package namespace. So
in the instance given above, channel names might be "input" for the upper
level, and "input.csv", "input.xls" and "input.gnu" for the sub-levels.
There is no arbitrary limit to the depth of nesting.
"""
def __init__(self, name, level=NOTSET):
"""
Initialize the logger with a name and an optional level.
"""
Filterer.__init__(self)
self.name = name # 指定name,也就是之前的root
self.level = _checkLevel(level) # 指定logger level
self.parent = None
self.propagate = True
self.handlers = []
self.disabled = False
self._cache = {}
def info(self, msg, *args, **kwargs):
"""
Log 'msg % args' with severity 'INFO'.
To pass exception information, use the keyword argument exc_info with
a true value, e.g.
logger.info("Houston, we have a %s", "interesting problem", exc_info=1)
"""
# 这步判断是为了判断是否该logger level可以被输出
if self.isEnabledFor(INFO):
self._log(INFO, msg, args, **kwargs)
def getEffectiveLevel(self):
"""
Get the effective level for this logger.
Loop through this logger and its parents in the logger hierarchy,
looking for a non-zero logging level. Return the first one found.
"""
# 寻找父级logger level
logger = self
while logger:
if logger.level:
return logger.level
logger = logger.parent
return NOTSET
def isEnabledFor(self, level):
"""
Is this logger enabled for level 'level'?
"""
try:
return self._cache[level]
except KeyError:
# 又出现的加锁**作
_acquireLock()
if self.manager.disable >= level:
is_enabled = self._cache[level] = False
else:
is_enabled = self._cache[level] = level >= self.getEffectiveLevel()
_releaseLock()
return is_enabled
root是RootLogger的实例,RootLogger继承于Logger,通过_log来统一记录日志,而在_log之前会有个logger level的判断
# 用来获取堆栈中的第一个调用者
# _srcfile is used when walking the stack to check when we've got the first
# caller stack frame, by skipping frames whose filename is that of this
# module's source. It therefore should contain the filename of this module's
# source file.
#
# Ordinarily we would use __file__ for this, but frozen modules don't always
# have __file__ set, for some reason (see Issue #21736). Thus, we get the
# filename from a handy code object from a function defined in this module.
# (There's no particular reason for picking addLevelName.)
#
_srcfile = os.path.normcase(addLevelName.__code__.co_filename)
# _srcfile is only used in conjunction with sys._getframe().
# To provide compatibility with older versions of Python, set _srcfile
# to None if _getframe() is not available; this value will prevent
# findCaller() from being called. You can also do this if you want to avoid
# the overhead of fetching caller information, even when _getframe() is
# available.
#if not hasattr(sys, '_getframe'):
# _srcfile = None
def _log(self, level, msg, args, exc_info=None, extra=None, stack_info=False):
"""
Low-level logging routine which creates a LogRecord and then calls
all the handlers of this logger to handle the record.
"""
sinfo = None
if _srcfile:
#IronPython doesn't track Python frames, so findCaller raises an
#exception on some versions of IronPython. We trap it here so that
#IronPython can use logging.
try:
fn, lno, func, sinfo = self.findCaller(stack_info)
except ValueError: # pragma: no cover
fn, lno, func = "(unknown file)", 0, "(unknown function)"
else: # pragma: no cover
fn, lno, func = "(unknown file)", 0, "(unknown function)"
if exc_info:
if isinstance(exc_info, BaseException):
exc_info = (type(exc_info), exc_info, exc_info.__traceback__)
elif not isinstance(exc_info, tuple):
exc_info = sys.exc_info()
# 通过makeRecord生成一条日志记录
record = self.makeRecord(self.name, level, fn, lno, msg, args,
exc_info, func, extra, sinfo)
# 处理
self.handle(record)
def findCaller(self, stack_info=False):
"""
通过调用堆栈获取文件名、行数和调用者
Find the stack frame of the caller so that we can note the source
file name, line number and function name.
"""
f = currentframe()
#On some versions of IronPython, currentframe() returns None if
#IronPython isn't run with -X:Frames.
if f is not None:
f = f.f_back
rv = "(unknown file)", 0, "(unknown function)", None
while hasattr(f, "f_code"):
co = f.f_code
filename = os.path.normcase(co.co_filename)
if filename == _srcfile:
f = f.f_back
continue
sinfo = None
if stack_info:
sio = io.StringIO()
sio.write('Stack (most recent call last):n')
traceback.print_stack(f, file=sio)
sinfo = sio.getvalue()
if sinfo[-1] == 'n':
sinfo = sinfo[:-1]
sio.close()
rv = (co.co_filename, f.f_lineno, co.co_name, sinfo)
break
return rv
def makeRecord(self, name, level, fn, lno, msg, args, exc_info,
func=None, extra=None, sinfo=None):
"""
A factory method which can be overridden in subclasses to create
specialized LogRecords.
"""
# 生成_logRecordFactory的实例
rv = _logRecordFactory(name, level, fn, lno, msg, args, exc_info, func,
sinfo)
if extra is not None:
for key in extra:
if (key in ["message", "asctime"]) or (key in rv.__dict__):
raise KeyError("Attempt to overwrite %r in LogRecord" % key)
rv.__dict__[key] = extra[key]
return rv
def handle(self, record):
"""
Call the handlers for the specified record.
This method is used for unpickled records received from a socket, as
well as those created locally. Logger-level filtering is applied.
"""
if (not self.disabled) and self.filter(record):
self.callHandlers(record)
def callHandlers(self, record):
"""
Pass a record to all relevant handlers.
Loop through all handlers for this logger and its parents in the
logger hierarchy. If no handler was found, output a one-off error
message to sys.stderr. Stop searching up the hierarchy whenever a
logger with the "propagate" attribute set to zero is found – that
will be the last logger whose handlers are called.
"""
c = self
found = 0
# 轮询自身绑定的handlers,并调用handle方法来处理该record实例,这里有点类似于import的流程,调用sys.meta_path的importer来处理path,也是同样的道理,这里我们回忆之前的rootLogger,我们调用baseConfig来初始化使FileHandler绑定到root,第二调用root.info,最终就来到了这个方法,调用到了FileHandler.handle方法来处理
while c:
for hdlr in c.handlers:
found = found + 1
if record.levelno >= hdlr.level:
hdlr.handle(record)
if not c.propagate:
c = None #break out
else:
c = c.parent
if (found == 0):
if lastResort:
if record.levelno >= lastResort.level:
lastResort.handle(record)
elif raiseExceptions and not self.manager.emittedNoHandlerWarning:
sys.stderr.write("No handlers could be found for logger"
" "%s"n" % self.name)
self.manager.emittedNoHandlerWarning = True
继续来看FileHandler
class FileHandler(StreamHandler):
def _open(self):
"""
Open the current base file with the (original) mode and encoding.
Return the resulting stream.
"""
return open(self.baseFilename, self.mode, encoding=self.encoding)
def emit(self, record):
"""
Emit a record.
If the stream was not opened because 'delay' was specified in the
constructor, open it before calling the superclass's emit.
"""
# 打开文件句柄(文件流)
if self.stream is None:
self.stream = self._open()
# 调用StreamHandler的emit方法
StreamHandler.emit(self, record)
class StreamHandler(Handler):
def flush(self):
"""
Flushes the stream.
"""
# 同样时加锁刷入
self.acquire()
try:
if self.stream and hasattr(self.stream, "flush"):
self.stream.flush()
finally:
self.release()
def emit(self, record):
"""
Emit a record.
If a formatter is specified, it is used to format the record.
The record is then written to the stream with a trailing newline. If
exception information is present, it is formatted using
traceback.print_exception and appended to the stream. If the stream
has an 'encoding' attribute, it is used to determine how to do the
output to the stream.
"""
try:
msg = self.format(record)
stream = self.stream
# issue 35046: merged two stream.writes into one.
# 写入流的缓冲区,执行flush
stream.write(msg + self.terminator)
self.flush()
except RecursionError: # See issue 36272
raise
except Exception:
self.handleError(record)
class Handler(Filterer):
# FileHandler的handle方法来源于祖父辈的Handler
def filter(self, record):
"""
Determine if a record is loggable by consulting all the filters.
The default is to allow the record to be logged; any filter can veto
this and the record is then dropped. Returns a zero value if a record
is to be dropped, else non-zero.
.. versionchanged:: 3.2
Allow filters to be just callables.
"""
rv = True
for f in self.filters:
if hasattr(f, 'filter'):
result = f.filter(record)
else:
result = f(record) # assume callable – will raise if not
if not result:
rv = False
break
return rv
def handle(self, record):
"""
Conditionally emit the specified logging record.
Emission depends on filters which may have been added to the handler.
Wrap the actual emission of the record with acquisition/release of
the I/O thread lock. Returns whether the filter passed the record for
emission.
"""
# 先对日志进行过滤处理再调用子类重写的emit方法执行真正的写入逻辑
rv = self.filter(record)
if rv:
self.acquire()
try:
self.emit(record)
finally:
self.release()
return rv
我们跟踪完了整个logging.info背后的流程,下面我们结合上面的代码以及官方的Logging Flow来梳理logging的流程框架
1.2 Logging 流程框架
源码在 python 自己的 lib/logging/ 下,主要内容都在 __init__.py 里,根据流程图以及我们之前分析的源码来理解下面四个组件以及日志结构体的定义
Logger,核心组件,可以挂载若干个 Handler以及若干个 Filter,定义要响应的命名空间和日志级别Handler,可以挂载一个 Formatter和若干个 Filter,定义了要响应日志级别和输出方式Filter,虽然是过滤器,负责对输入的 LogRecord 做判断,返回 True/False 来决定挂载的 Logger 或 Handler 是否要处理当前日志,但是也可以拿来当做中间件来使用,可以自定义规则来改写LogRecord,继续传递给后续的Filter/Handler/LoggerFormatter,最终日志的格式化组件LogRecord,单条日志的结构体
根据流程图来看,主流程如下
日志打印请求到Logger后,第一判断当前Logger是否要处理这个级别,不处理的直接舍弃(第一层级别控制)生成一条LogRecord,会把包括调用来源等信息都一起打包好,依次调用Logger挂载的Filter链来处理一旦有Filter类的检测结果返回是False,则丢弃日志否则传给Logger挂载的Handler链中依次处理(进入Handler流程)如果开启了propagate属性,也就是“向上传播”,会将当前的LogRecord 传递给父类的Logger来进行处理,直接从第4步开始执行(不会触发第一层级别控制)
Handler流程
判当前Handler 是否要处理这个级别,不处理的直接舍弃(第二层级别控制)将收到的LogRecord 依次调用Handler挂载的Filter链来处理同理,调用Formatter2. 多进程场景下的Logging2.1 多进程场景Logging问题分析
Logging模块是线程安全的,我们在之前的代码中可以看到很多处使用到了threading.RLock(),特别是在调用info/error等方法打印日志时,最终都会调用顶级父类的handle方法,也就是
# logging/__init__.py
def handle(self, record):
# 先对日志进行过滤处理再调用子类重写的emit方法执行真正的写入逻辑
rv = self.filter(record)
if rv:
self.acquire()
try:
self.emit(record)
finally:
self.release()
return rv
这使得在多线程环境下可以保证同一时间只有一个线程可以调用handle方法进行写入
然而,另一个可能被忽视的场景是在多进程环境下引发的种种问题,我们在部署Python Web项目时,通常会以多进程的方式来启动,这就可能导致以下的几种问题:
日志紊乱:比如两个进程分别输出xxxx和yyyy两条日志,那么在文件中可能会得到类似xxyxyxyy这样的结果日志丢失:虽然读写日志是使用O_APPEND模式,保证了写文件的一致性,但是由于buffer的存在(数据先写入buffer,再触发flush机制刷入磁盘),fwrite的**作并不是多进程安全的日志丢失的另一种情况:使用RotatingFileHandler或者是TimerRotatingFileHandler的时候,在切换文件的时候会导致进程拿到的文件句柄不同,导致新文件被重复创建、数据写入旧文件2.2 多进程场景Logging解决方案
为了应对上述可能出现的情况,以下列举几种解决方案:
2.2.1 concurrent-log-handler模块(文件锁模式)# concurrent_log_handler/__init__.[y]
# 继承自logging的BaseRotatingHandler
class ConcurrentRotatingFileHandler(BaseRotatingHandler):
# 具体写入逻辑
def emit(self, record):
try:
msg = self.format(record)
# 加锁逻辑
try:
self._do_lock()
# 常规**作shouldRollover、doRollover做文件切分
try:
if self.shouldRollover(record):
self.doRollover()
except Exception as e:
self._console_log("Unable to do rollover: %s" % (e,), stack=True)
# Continue on anyway
self.do_write(msg)
finally:
self._do_unlock()
except (KeyboardInterrupt, SystemExit):
raise
except Exception:
self.handleError(record)
def _do_lock(self):
# 判断是否已被锁
if self.is_locked:
return # already locked… recursive?
# 触发文件锁
self._open_lockfile()
if self.stream_lock:
for i in range(10):
# noinspection PyBroadException
try:
# 调用portalocker lock的方法
lock(self.stream_lock, LOCK_EX)
self.is_locked = True
break
except Exception:
continue
else:
raise RuntimeError("Cannot acquire lock after 10 attempts")
else:
self._console_log("No self.stream_lock to lock", stack=True)
def _open_lockfile(self):
"""
改变文件权限
"""
if self.stream_lock and not self.stream_lock.closed:
self._console_log("Lockfile already open in this process")
return
lock_file = self.lockFilename
self._console_log(
"concurrent-log-handler %s opening %s" % (hash(self), lock_file), stack=False)
with self._alter_umask():
self.stream_lock = open(lock_file, "wb", buffering=0)
self._do_chown_and_chmod(lock_file)
def _do_unlock(self):
if self.stream_lock:
if self.is_locked:
try:
unlock(self.stream_lock)
finally:
self.is_locked = False
self.stream_lock.close()
self.stream_lock = None
else:
self._console_log("No self.stream_lock to unlock", stack=True)
# portalocker/portalocker.py
def lock(file_: typing.IO, flags: constants.LockFlags):
if flags & constants.LockFlags.SHARED:
…
else:
if flags & constants.LockFlags.NON_BLOCKING:
mode = msvcrt.LK_NBLCK
else:
mode = msvcrt.LK_LOCK
# windows locks byte ranges, so make sure to lock from file start
try:
savepos = file_.tell()
if savepos:
# [ ] test exclusive lock fails on seek here
# [ ] test if shared lock passes this point
file_.seek(0)
# [x] check if 0 param locks entire file (not documented in
# Python)
# [x] fails with "IOError: [Errno 13] Permission denied",
# but -1 seems to do the trick
try:
msvcrt.locking(file_.fileno(), mode, lock_length)
except IOError as exc_value:
# [ ] be more specific here
raise exceptions.LockException(
exceptions.LockException.LOCK_FAILED,
exc_value.strerror,
fh=file_)
finally:
if savepos:
file_.seek(savepos)
except IOError as exc_value:
raise exceptions.LockException(
exceptions.LockException.LOCK_FAILED, exc_value.strerror,
fh=file_)
"""
调用C运行时的文件锁机制
msvcrt.locking(fd, mode, nbytes)
Lock part of a file based on file descriptor fd from the C runtime. Raises OSError on failure. The locked region of the file extends from the current file position for nbytes bytes, and may continue beyond the end of the file. mode must be one of the LK_* constants listed below. Multiple regions in a file may be locked at the same time, but may not overlap. Adjacent regions are not merged; they must be unlocked individually.
Raises an auditing event msvcrt.locking with arguments fd, mode, nbytes.
"""
归根到底,就是在emit方法触发时调用了文件锁机制,将多个进程并发调用强制限制为单进程顺序调用,确保了日志写入的准确,但是在效率方面,频繁的对文件修改权限、加锁以及锁抢占机制都会造成效率低下的问题。
2.2.2 针对日志切分场景的复写doRollover方法以及复写FileHandler类
当然,除了上述的文件加锁方式,我们也可以自定义重写TimeRotatingFileHandler类或者FileHandler类,加入简单的多进程加锁的逻辑,例如fcntl.flock
static PyObject *
fcntl_flock_impl(PyObject *module, int fd, int code)
/*[clinic end generated code: output=84059e2b37d2fc64 input=0bfc00f795953452]*/
{
int ret;
int async_err = 0;
if (PySys_Audit("fcntl.flock", "ii", fd, code) < 0) {
return NULL;
}
# 触发linux flock命令加锁
#ifdef HAVE_FLOCK
do {
Py_BEGIN_ALLOW_THREADS
ret = flock(fd, code);
Py_END_ALLOW_THREADS
} while (ret == -1 && errno == EINTR && !(async_err = PyErr_CheckSignals()));
#else
#ifndef LOCK_SH
#define LOCK_SH 1 /* shared lock */
#define LOCK_EX 2 /* exclusive lock */
#define LOCK_NB 4 /* don't block when locking */
#define LOCK_UN 8 /* unlock */
#endif
{
struct flock l;
if (code == LOCK_UN)
l.l_type = F_UNLCK;
else if (code & LOCK_SH)
l.l_type = F_RDLCK;
else if (code & LOCK_EX)
l.l_type = F_WRLCK;
else {
PyErr_SetString(PyExc_ValueError,
"unrecognized flock argument");
return NULL;
}
l.l_whence = l.l_start = l.l_len = 0;
do {
Py_BEGIN_ALLOW_THREADS
ret = fcntl(fd, (code & LOCK_NB) ? F_SETLK : F_SETLKW, &l);
Py_END_ALLOW_THREADS
} while (ret == -1 && errno == EINTR && !(async_err = PyErr_CheckSignals()));
}
#endif /* HAVE_FLOCK */
if (ret < 0) {
return !async_err ? PyErr_SetFromErrno(PyExc_OSError) : NULL;
}
Py_RETURN_NONE;
}2.2.3 Master/Worker日志收集(Socket/Queue模式)
这种方式也是被官方主推的方式
Although logging is thread-safe, and logging to a single file from multiple threads in a single process is supported, logging to a single file from multiple processes is not supported, because there is no standard way to serialize access to a single file across multiple processes in Python. If you need to log to a single file from multiple processes, one way of doing this is to have all the processes log to a SocketHandler, and have a separate process which implements a socket server which reads from the socket and logs to file.(如果你需要将多个进程中的日志记录至单个文件,有一个方案是让所有进程都将日志记录至一个 SocketHandler,第二用一个实现了套接字服务器的单独进程一边从套接字中读取一边将日志记录至文件) (If you prefer, you can dedicate one thread in one of the existing processes to perform this function.) This section documents this approach in more detail and includes a working socket receiver which can be used as a starting point for you to adapt in your own applications.
Alternatively, you can use a Queue and a QueueHandler to send all logging events to one of the processes in your multi-process application. (你也可以使用 Queue 和 QueueHandler 将所有的日志**发送至你的多进程应用的一个进程中。)The following example script demonstrates how you can do this; in the example a separate listener process listens for events sent by other processes and logs them according to its own logging configuration. Although the example only demonstrates one way of doing it (for example, you may want to use a listener thread rather than a separate listener process – the implementation would be **ogous) it does allow for completely different logging configurations for the listener and the other processes in your application, and can be used as the basis for code meeting your own specific requirements:
看看QueueHandler的案例
import logging
import logging.config
import logging.handlers
from multiprocessing import Process, Queue
import random
import threading
import time
def logger_thread(q):
"""
单独的日志记录线程
"""
while True:
record = q.get()
if record is None:
break
# 获取record实例中的logger
logger = logging.getLogger(record.name)
# 调用logger的handle方法处理
logger.handle(record)
def worker_process(q):
# 日志写入进程
qh = logging.handlers.QueueHandler(q)
root = logging.getLogger()
root.setLevel(logging.DEBUG)
# 绑定QueueHandler到logger
root.addHandler(qh)
levels = [logging.DEBUG, logging.INFO, logging.WARNING, logging.ERROR,
logging.CRITICAL]
loggers = ['foo', 'foo.bar', 'foo.bar.baz',
'spam', 'spam.ham', 'spam.ham.eggs']
for i in range(100):
lvl = random.choice(levels)
logger = logging.getLogger(random.choice(loggers))
logger.log(lvl, 'Message no. %d', i)
if __name__ == '__main__':
q = Queue()
# 省略一大推配置
workers = []
# 多进程写入日志到Queue
for i in range(5):
wp = Process(target=worker_process, name='worker %d' % (i + 1), args=(q,))
workers.append(wp)
wp.start()
logging.config.dictConfig(d)
# 启动子线程负责日志收集写入
lp = threading.Thread(target=logger_thread, args=(q,))
lp.start()
# At this point, the main process could do some useful work of its own
# Once it's done that, it can wait for the workers to terminate…
for wp in workers:
wp.join()
# And now tell the logging thread to finish up, too
q.put(None)
lp.join()
看看SocketHandler的案例
# 发送端
import logging, logging.handlers
rootLogger = logging.getLogger('')
rootLogger.setLevel(logging.DEBUG)
# 指定ip、端口
socketHandler = logging.handlers.SocketHandler('localhost',
logging.handlers.DEFAULT_TCP_LOGGING_PORT)
# don't bother with a formatter, since a socket handler sends the event as
# an unformatted pickle
rootLogger.addHandler(socketHandler)
# Now, we can log to the root logger, or any other logger. First the root…
logging.info('Jackdaws love my big sphinx of quartz.')
# Now, define a couple of other loggers which might represent areas in your
# application:
logger1 = logging.getLogger('myapp.area1')
logger2 = logging.getLogger('myapp.area2')
logger1.debug('Quick zephyrs blow, vexing daft Jim.')
logger1.info('How quickly daft jumping zebras vex.')
logger2.warning('Jail zesty vixen who grabbed pay from quack.')
logger2.error('The five boxing wizards jump quickly.')
# 接收端
import pickle
import logging
import logging.handlers
import socketserver
import struct
class LogRecordStreamHandler(socketserver.StreamRequestHandler):
"""Handler for a streaming logging request.
This basically logs the record using whatever logging policy is
configured locally.
"""
def handle(self):
"""
Handle multiple requests – each expected to be a 4-byte length,
followed by the LogRecord in pickle format. Logs the record
according to whatever policy is configured locally.
"""
while True:
# 接收数据的流程
chunk = self.connection.recv(4)
if len(chunk) < 4:
break
slen = struct.unpack('>L', chunk)[0]
chunk = self.connection.recv(slen)
while len(chunk) < slen:
chunk = chunk + self.connection.recv(slen – len(chunk))
obj = self.unPickle(chunk)
# 生成LodRecord实例,调用handleLogRecord处理
record = logging.makeLogRecord(obj)
self.handleLogRecord(record)
def unPickle(self, data):
return pickle.loads(data)
def handleLogRecord(self, record):
# if a name is specified, we use the named logger rather than the one
# implied by the record.
if self.server.logname is not None:
name = self.server.logname
else:
name = record.name
logger = logging.getLogger(name)
# N.B. EVERY record gets logged. This is because Logger.handle
# is normally called AFTER logger-level filtering. If you want
# to do filtering, do it at the client end to save wasting
# cycles and network bandwidth!
logger.handle(record)
class LogRecordSocketReceiver(socketserver.ThreadingTCPServer):
"""
Simple TCP socket-based logging receiver suitable for testing.
"""
allow_reuse_address = True
def __init__(self, host='localhost',
port=logging.handlers.DEFAULT_TCP_LOGGING_PORT,
handler=LogRecordStreamHandler):
socketserver.ThreadingTCPServer.__init__(self, (host, port), handler)
self.abort = 0
self.timeout = 1
self.logname = None
def serve_until_stopped(self):
import select
abort = 0
while not abort:
# select方法接收端口数据
rd, wr, ex = select.select([self.socket.fileno()],
[], [],
self.timeout)
if rd:
# 调用LogRecordStreamHandler的handle方法处理
self.handle_request()
abort = self.abort
def main():
logging.basicConfig(
format='%(relativeCreated)5d %(name)-15s %(levelname)-8s %(message)s')
tcpserver = LogRecordSocketReceiver()
print('About to start TCP server…')
tcpserver.serve_until_stopped()
if __name__ == '__main__':
main()
有关于 Master/Worker的方式就是上述的两种模式,日志写入的效率不受并发的影响,最终取决于写入线程。此外,对于日志的写入慢、阻塞问题,同样可以使用QueueHandlers以及其扩展的QueueListener来处理。
作者:技术拆解官原文链接:https://juejin.cn/post/6945301448934719518
拓展知识:
前沿拓展:
推荐学习22天试水Python社招,历经“百度+字节+天融”等6家 金三即过,这300道python高频面试都没刷,银四怎么闯?
前言
Logging日志记录框架是Python内置打印模块,它对很多Python开发者来说是既熟悉又陌生,确实,它使用起来很简单,只需要我们简单一行代码,就可以打印出日志
import logging
logging.debug("This is a debug log.")
logging.info("This is a info log.")
logging.warning("This is a warning log.")
logging.error("This is a error log.")
logging.critical("This is a critical log.")
# output
WARNING:root:This is a warning log.
ERROR:root:This is a error log.
CRITICAL:root:This is a critical log.
但是对于我们在实际项目中需要基于Logging来开发日志框架时,常常会遇到各种各样的问题,例如性能方面的多进程下滚动日志记录丢失、日志记录效率低的问题以及在二次开发时因为没有理解Logging内部流程导致没有利用到Logging的核心机制等等。
接下来,我们就从一行代码来深挖Logging System的秘密
1. 深入Logging模块源码1.1 logging.info做了什么?
logging.info作为大多数人使用logging模块的第一行代码,隐藏了很多实现细节,以至于我们在最初都只关注功能,而忽略了它的内部细节
import logging
logging.info("This is a info log.")
# logging/__init__.py
def info(msg, *args, **kwargs):
"""
Log a message with severity 'INFO' on the root logger. If the logger has
no handlers, call basicConfig() to add a console handler with a pre-defined
format.
"""
# 没有绑定handlers就调用basicConfig方法
if len(root.handlers) == 0:
basicConfig()
root.info(msg, *args, **kwargs)
_lock = threading.RLock()
def _acquireLock():
"""
Acquire the module-level lock for serializing access to shared data.
This should be released with _releaseLock().
"""
if _lock:
_lock.acquire()
def _releaseLock():
"""
Release the module-level lock acquired by calling _acquireLock().
"""
if _lock:
_lock.release()
def basicConfig(**kwargs):
"""
很方便的一步到位的配置方法创建一个StreamHandler打印日志到控制台
This function does nothing if the root logger already has handlers
configured. It is a convenience method intended for use by simple scripts
to do one-shot configuration of the logging package.
The default behaviour is to create a StreamHandler which writes to
sys.stderr, set a formatter using the BASIC_FORMAT format string, and
add the handler to the root logger.
"""
# Add thread safety in case someone mistakenly calls
# basicConfig() from multiple threads
# 为了确保多线程安全的写日志**作,做了加锁处理(如上,标准的多线程锁**作)
_acquireLock()
try:
if len(root.handlers) == 0:
# 对于handler的处理,有filename就新建FileHandler,没有就选择StreamHandler
handlers = kwargs.pop("handlers", None)
if handlers is None:
if "stream" in kwargs and "filename" in kwargs:
raise ValueError("'stream' and 'filename' should not be "
"specified together")
else:
if "stream" in kwargs or "filename" in kwargs:
raise ValueError("'stream' or 'filename' should not be "
"specified together with 'handlers'")
if handlers is None:
filename = kwargs.pop("filename", None)
mode = kwargs.pop("filemode", 'a')
if filename:
h = FileHandler(filename, mode)
else:
stream = kwargs.pop("stream", None)
h = StreamHandler(stream)
handlers = [h]
dfs = kwargs.pop("datefmt", None)
style = kwargs.pop("style", '%')
if style not in _STYLES:
raise ValueError('Style must be one of: %s' % ','.join(
_STYLES.keys()))
fs = kwargs.pop("format", _STYLES[style][1])
fmt = Formatter(fs, dfs, style)
# 绑定handler到root
for h in handlers:
if h.formatter is None:
h.setFormatter(fmt)
root.addHandler(h)
level = kwargs.pop("level", None)
if level is not None:
root.setLevel(level)
if kwargs:
keys = ', '.join(kwargs.keys())
raise ValueError('Unrecognised argument(s): %s' % keys)
finally:
_releaseLock()
到目前为止,可以看到logging.info通过调用basicConfig()来完成初始化handler之后才开始正式打印,而basicConfig()的逻辑是通过多线程锁状态下的一个初始化handler->绑定root的**作,那这个root代表了什么呢?
# logging/__init__.py
root = RootLogger(WARNING)
Logger.root = root
Logger.manager = Manager(Logger.root)
class RootLogger(Logger):
"""
A root logger is not that different to any other logger, except that
it must have a logging level and there is only one instance of it in
the hierarchy.
"""
def __init__(self, level):
"""
Initialize the logger with the name "root".
"""
# 调用父类的初始化,传入了root和WARNING两个参数,所以我们直接调用logging.info时是不能输出任何信息的,因为logger level初始化时就被指定成了WARNING
Logger.__init__(self, "root", level)
def __reduce__(self):
return getLogger, ()
class Logger(Filterer):
"""
Instances of the Logger class represent a single logging channel. A
"logging channel" indicates an area of an application. Exactly how an
"area" is defined is up to the application developer. Since an
application can have any number of areas, logging channels are identified
by a unique string. Application areas can be nested (e.g. an area
of "input processing" might include sub-areas "read CSV files", "read
XLS files" and "read Gnumeric files"). To cater for this natural nesting,
channel names are organized into a namespace hierarchy where levels are
separated by periods, much like the Java or Python package namespace. So
in the instance given above, channel names might be "input" for the upper
level, and "input.csv", "input.xls" and "input.gnu" for the sub-levels.
There is no arbitrary limit to the depth of nesting.
"""
def __init__(self, name, level=NOTSET):
"""
Initialize the logger with a name and an optional level.
"""
Filterer.__init__(self)
self.name = name # 指定name,也就是之前的root
self.level = _checkLevel(level) # 指定logger level
self.parent = None
self.propagate = True
self.handlers = []
self.disabled = False
self._cache = {}
def info(self, msg, *args, **kwargs):
"""
Log 'msg % args' with severity 'INFO'.
To pass exception information, use the keyword argument exc_info with
a true value, e.g.
logger.info("Houston, we have a %s", "interesting problem", exc_info=1)
"""
# 这步判断是为了判断是否该logger level可以被输出
if self.isEnabledFor(INFO):
self._log(INFO, msg, args, **kwargs)
def getEffectiveLevel(self):
"""
Get the effective level for this logger.
Loop through this logger and its parents in the logger hierarchy,
looking for a non-zero logging level. Return the first one found.
"""
# 寻找父级logger level
logger = self
while logger:
if logger.level:
return logger.level
logger = logger.parent
return NOTSET
def isEnabledFor(self, level):
"""
Is this logger enabled for level 'level'?
"""
try:
return self._cache[level]
except KeyError:
# 又出现的加锁**作
_acquireLock()
if self.manager.disable >= level:
is_enabled = self._cache[level] = False
else:
is_enabled = self._cache[level] = level >= self.getEffectiveLevel()
_releaseLock()
return is_enabled
root是RootLogger的实例,RootLogger继承于Logger,通过_log来统一记录日志,而在_log之前会有个logger level的判断
# 用来获取堆栈中的第一个调用者
# _srcfile is used when walking the stack to check when we've got the first
# caller stack frame, by skipping frames whose filename is that of this
# module's source. It therefore should contain the filename of this module's
# source file.
#
# Ordinarily we would use __file__ for this, but frozen modules don't always
# have __file__ set, for some reason (see Issue #21736). Thus, we get the
# filename from a handy code object from a function defined in this module.
# (There's no particular reason for picking addLevelName.)
#
_srcfile = os.path.normcase(addLevelName.__code__.co_filename)
# _srcfile is only used in conjunction with sys._getframe().
# To provide compatibility with older versions of Python, set _srcfile
# to None if _getframe() is not available; this value will prevent
# findCaller() from being called. You can also do this if you want to avoid
# the overhead of fetching caller information, even when _getframe() is
# available.
#if not hasattr(sys, '_getframe'):
# _srcfile = None
def _log(self, level, msg, args, exc_info=None, extra=None, stack_info=False):
"""
Low-level logging routine which creates a LogRecord and then calls
all the handlers of this logger to handle the record.
"""
sinfo = None
if _srcfile:
#IronPython doesn't track Python frames, so findCaller raises an
#exception on some versions of IronPython. We trap it here so that
#IronPython can use logging.
try:
fn, lno, func, sinfo = self.findCaller(stack_info)
except ValueError: # pragma: no cover
fn, lno, func = "(unknown file)", 0, "(unknown function)"
else: # pragma: no cover
fn, lno, func = "(unknown file)", 0, "(unknown function)"
if exc_info:
if isinstance(exc_info, BaseException):
exc_info = (type(exc_info), exc_info, exc_info.__traceback__)
elif not isinstance(exc_info, tuple):
exc_info = sys.exc_info()
# 通过makeRecord生成一条日志记录
record = self.makeRecord(self.name, level, fn, lno, msg, args,
exc_info, func, extra, sinfo)
# 处理
self.handle(record)
def findCaller(self, stack_info=False):
"""
通过调用堆栈获取文件名、行数和调用者
Find the stack frame of the caller so that we can note the source
file name, line number and function name.
"""
f = currentframe()
#On some versions of IronPython, currentframe() returns None if
#IronPython isn't run with -X:Frames.
if f is not None:
f = f.f_back
rv = "(unknown file)", 0, "(unknown function)", None
while hasattr(f, "f_code"):
co = f.f_code
filename = os.path.normcase(co.co_filename)
if filename == _srcfile:
f = f.f_back
continue
sinfo = None
if stack_info:
sio = io.StringIO()
sio.write('Stack (most recent call last):n')
traceback.print_stack(f, file=sio)
sinfo = sio.getvalue()
if sinfo[-1] == 'n':
sinfo = sinfo[:-1]
sio.close()
rv = (co.co_filename, f.f_lineno, co.co_name, sinfo)
break
return rv
def makeRecord(self, name, level, fn, lno, msg, args, exc_info,
func=None, extra=None, sinfo=None):
"""
A factory method which can be overridden in subclasses to create
specialized LogRecords.
"""
# 生成_logRecordFactory的实例
rv = _logRecordFactory(name, level, fn, lno, msg, args, exc_info, func,
sinfo)
if extra is not None:
for key in extra:
if (key in ["message", "asctime"]) or (key in rv.__dict__):
raise KeyError("Attempt to overwrite %r in LogRecord" % key)
rv.__dict__[key] = extra[key]
return rv
def handle(self, record):
"""
Call the handlers for the specified record.
This method is used for unpickled records received from a socket, as
well as those created locally. Logger-level filtering is applied.
"""
if (not self.disabled) and self.filter(record):
self.callHandlers(record)
def callHandlers(self, record):
"""
Pass a record to all relevant handlers.
Loop through all handlers for this logger and its parents in the
logger hierarchy. If no handler was found, output a one-off error
message to sys.stderr. Stop searching up the hierarchy whenever a
logger with the "propagate" attribute set to zero is found – that
will be the last logger whose handlers are called.
"""
c = self
found = 0
# 轮询自身绑定的handlers,并调用handle方法来处理该record实例,这里有点类似于import的流程,调用sys.meta_path的importer来处理path,也是同样的道理,这里我们回忆之前的rootLogger,我们调用baseConfig来初始化使FileHandler绑定到root,第二调用root.info,最终就来到了这个方法,调用到了FileHandler.handle方法来处理
while c:
for hdlr in c.handlers:
found = found + 1
if record.levelno >= hdlr.level:
hdlr.handle(record)
if not c.propagate:
c = None #break out
else:
c = c.parent
if (found == 0):
if lastResort:
if record.levelno >= lastResort.level:
lastResort.handle(record)
elif raiseExceptions and not self.manager.emittedNoHandlerWarning:
sys.stderr.write("No handlers could be found for logger"
" "%s"n" % self.name)
self.manager.emittedNoHandlerWarning = True
继续来看FileHandler
class FileHandler(StreamHandler):
def _open(self):
"""
Open the current base file with the (original) mode and encoding.
Return the resulting stream.
"""
return open(self.baseFilename, self.mode, encoding=self.encoding)
def emit(self, record):
"""
Emit a record.
If the stream was not opened because 'delay' was specified in the
constructor, open it before calling the superclass's emit.
"""
# 打开文件句柄(文件流)
if self.stream is None:
self.stream = self._open()
# 调用StreamHandler的emit方法
StreamHandler.emit(self, record)
class StreamHandler(Handler):
def flush(self):
"""
Flushes the stream.
"""
# 同样时加锁刷入
self.acquire()
try:
if self.stream and hasattr(self.stream, "flush"):
self.stream.flush()
finally:
self.release()
def emit(self, record):
"""
Emit a record.
If a formatter is specified, it is used to format the record.
The record is then written to the stream with a trailing newline. If
exception information is present, it is formatted using
traceback.print_exception and appended to the stream. If the stream
has an 'encoding' attribute, it is used to determine how to do the
output to the stream.
"""
try:
msg = self.format(record)
stream = self.stream
# issue 35046: merged two stream.writes into one.
# 写入流的缓冲区,执行flush
stream.write(msg + self.terminator)
self.flush()
except RecursionError: # See issue 36272
raise
except Exception:
self.handleError(record)
class Handler(Filterer):
# FileHandler的handle方法来源于祖父辈的Handler
def filter(self, record):
"""
Determine if a record is loggable by consulting all the filters.
The default is to allow the record to be logged; any filter can veto
this and the record is then dropped. Returns a zero value if a record
is to be dropped, else non-zero.
.. versionchanged:: 3.2
Allow filters to be just callables.
"""
rv = True
for f in self.filters:
if hasattr(f, 'filter'):
result = f.filter(record)
else:
result = f(record) # assume callable – will raise if not
if not result:
rv = False
break
return rv
def handle(self, record):
"""
Conditionally emit the specified logging record.
Emission depends on filters which may have been added to the handler.
Wrap the actual emission of the record with acquisition/release of
the I/O thread lock. Returns whether the filter passed the record for
emission.
"""
# 先对日志进行过滤处理再调用子类重写的emit方法执行真正的写入逻辑
rv = self.filter(record)
if rv:
self.acquire()
try:
self.emit(record)
finally:
self.release()
return rv
我们跟踪完了整个logging.info背后的流程,下面我们结合上面的代码以及官方的Logging Flow来梳理logging的流程框架
1.2 Logging 流程框架
源码在 python 自己的 lib/logging/ 下,主要内容都在 __init__.py 里,根据流程图以及我们之前分析的源码来理解下面四个组件以及日志结构体的定义
Logger,核心组件,可以挂载若干个 Handler以及若干个 Filter,定义要响应的命名空间和日志级别Handler,可以挂载一个 Formatter和若干个 Filter,定义了要响应日志级别和输出方式Filter,虽然是过滤器,负责对输入的 LogRecord 做判断,返回 True/False 来决定挂载的 Logger 或 Handler 是否要处理当前日志,但是也可以拿来当做中间件来使用,可以自定义规则来改写LogRecord,继续传递给后续的Filter/Handler/LoggerFormatter,最终日志的格式化组件LogRecord,单条日志的结构体
根据流程图来看,主流程如下
日志打印请求到Logger后,第一判断当前Logger是否要处理这个级别,不处理的直接舍弃(第一层级别控制)生成一条LogRecord,会把包括调用来源等信息都一起打包好,依次调用Logger挂载的Filter链来处理一旦有Filter类的检测结果返回是False,则丢弃日志否则传给Logger挂载的Handler链中依次处理(进入Handler流程)如果开启了propagate属性,也就是“向上传播”,会将当前的LogRecord 传递给父类的Logger来进行处理,直接从第4步开始执行(不会触发第一层级别控制)
Handler流程
判当前Handler 是否要处理这个级别,不处理的直接舍弃(第二层级别控制)将收到的LogRecord 依次调用Handler挂载的Filter链来处理同理,调用Formatter2. 多进程场景下的Logging2.1 多进程场景Logging问题分析
Logging模块是线程安全的,我们在之前的代码中可以看到很多处使用到了threading.RLock(),特别是在调用info/error等方法打印日志时,最终都会调用顶级父类的handle方法,也就是
# logging/__init__.py
def handle(self, record):
# 先对日志进行过滤处理再调用子类重写的emit方法执行真正的写入逻辑
rv = self.filter(record)
if rv:
self.acquire()
try:
self.emit(record)
finally:
self.release()
return rv
这使得在多线程环境下可以保证同一时间只有一个线程可以调用handle方法进行写入
然而,另一个可能被忽视的场景是在多进程环境下引发的种种问题,我们在部署Python Web项目时,通常会以多进程的方式来启动,这就可能导致以下的几种问题:
日志紊乱:比如两个进程分别输出xxxx和yyyy两条日志,那么在文件中可能会得到类似xxyxyxyy这样的结果日志丢失:虽然读写日志是使用O_APPEND模式,保证了写文件的一致性,但是由于buffer的存在(数据先写入buffer,再触发flush机制刷入磁盘),fwrite的**作并不是多进程安全的日志丢失的另一种情况:使用RotatingFileHandler或者是TimerRotatingFileHandler的时候,在切换文件的时候会导致进程拿到的文件句柄不同,导致新文件被重复创建、数据写入旧文件2.2 多进程场景Logging解决方案
为了应对上述可能出现的情况,以下列举几种解决方案:
2.2.1 concurrent-log-handler模块(文件锁模式)# concurrent_log_handler/__init__.[y]
# 继承自logging的BaseRotatingHandler
class ConcurrentRotatingFileHandler(BaseRotatingHandler):
# 具体写入逻辑
def emit(self, record):
try:
msg = self.format(record)
# 加锁逻辑
try:
self._do_lock()
# 常规**作shouldRollover、doRollover做文件切分
try:
if self.shouldRollover(record):
self.doRollover()
except Exception as e:
self._console_log("Unable to do rollover: %s" % (e,), stack=True)
# Continue on anyway
self.do_write(msg)
finally:
self._do_unlock()
except (KeyboardInterrupt, SystemExit):
raise
except Exception:
self.handleError(record)
def _do_lock(self):
# 判断是否已被锁
if self.is_locked:
return # already locked… recursive?
# 触发文件锁
self._open_lockfile()
if self.stream_lock:
for i in range(10):
# noinspection PyBroadException
try:
# 调用portalocker lock的方法
lock(self.stream_lock, LOCK_EX)
self.is_locked = True
break
except Exception:
continue
else:
raise RuntimeError("Cannot acquire lock after 10 attempts")
else:
self._console_log("No self.stream_lock to lock", stack=True)
def _open_lockfile(self):
"""
改变文件权限
"""
if self.stream_lock and not self.stream_lock.closed:
self._console_log("Lockfile already open in this process")
return
lock_file = self.lockFilename
self._console_log(
"concurrent-log-handler %s opening %s" % (hash(self), lock_file), stack=False)
with self._alter_umask():
self.stream_lock = open(lock_file, "wb", buffering=0)
self._do_chown_and_chmod(lock_file)
def _do_unlock(self):
if self.stream_lock:
if self.is_locked:
try:
unlock(self.stream_lock)
finally:
self.is_locked = False
self.stream_lock.close()
self.stream_lock = None
else:
self._console_log("No self.stream_lock to unlock", stack=True)
# portalocker/portalocker.py
def lock(file_: typing.IO, flags: constants.LockFlags):
if flags & constants.LockFlags.SHARED:
…
else:
if flags & constants.LockFlags.NON_BLOCKING:
mode = msvcrt.LK_NBLCK
else:
mode = msvcrt.LK_LOCK
# windows locks byte ranges, so make sure to lock from file start
try:
savepos = file_.tell()
if savepos:
# [ ] test exclusive lock fails on seek here
# [ ] test if shared lock passes this point
file_.seek(0)
# [x] check if 0 param locks entire file (not documented in
# Python)
# [x] fails with "IOError: [Errno 13] Permission denied",
# but -1 seems to do the trick
try:
msvcrt.locking(file_.fileno(), mode, lock_length)
except IOError as exc_value:
# [ ] be more specific here
raise exceptions.LockException(
exceptions.LockException.LOCK_FAILED,
exc_value.strerror,
fh=file_)
finally:
if savepos:
file_.seek(savepos)
except IOError as exc_value:
raise exceptions.LockException(
exceptions.LockException.LOCK_FAILED, exc_value.strerror,
fh=file_)
"""
调用C运行时的文件锁机制
msvcrt.locking(fd, mode, nbytes)
Lock part of a file based on file descriptor fd from the C runtime. Raises OSError on failure. The locked region of the file extends from the current file position for nbytes bytes, and may continue beyond the end of the file. mode must be one of the LK_* constants listed below. Multiple regions in a file may be locked at the same time, but may not overlap. Adjacent regions are not merged; they must be unlocked individually.
Raises an auditing event msvcrt.locking with arguments fd, mode, nbytes.
"""
归根到底,就是在emit方法触发时调用了文件锁机制,将多个进程并发调用强制限制为单进程顺序调用,确保了日志写入的准确,但是在效率方面,频繁的对文件修改权限、加锁以及锁抢占机制都会造成效率低下的问题。
2.2.2 针对日志切分场景的复写doRollover方法以及复写FileHandler类
当然,除了上述的文件加锁方式,我们也可以自定义重写TimeRotatingFileHandler类或者FileHandler类,加入简单的多进程加锁的逻辑,例如fcntl.flock
static PyObject *
fcntl_flock_impl(PyObject *module, int fd, int code)
/*[clinic end generated code: output=84059e2b37d2fc64 input=0bfc00f795953452]*/
{
int ret;
int async_err = 0;
if (PySys_Audit("fcntl.flock", "ii", fd, code) < 0) {
return NULL;
}
# 触发linux flock命令加锁
#ifdef HAVE_FLOCK
do {
Py_BEGIN_ALLOW_THREADS
ret = flock(fd, code);
Py_END_ALLOW_THREADS
} while (ret == -1 && errno == EINTR && !(async_err = PyErr_CheckSignals()));
#else
#ifndef LOCK_SH
#define LOCK_SH 1 /* shared lock */
#define LOCK_EX 2 /* exclusive lock */
#define LOCK_NB 4 /* don't block when locking */
#define LOCK_UN 8 /* unlock */
#endif
{
struct flock l;
if (code == LOCK_UN)
l.l_type = F_UNLCK;
else if (code & LOCK_SH)
l.l_type = F_RDLCK;
else if (code & LOCK_EX)
l.l_type = F_WRLCK;
else {
PyErr_SetString(PyExc_ValueError,
"unrecognized flock argument");
return NULL;
}
l.l_whence = l.l_start = l.l_len = 0;
do {
Py_BEGIN_ALLOW_THREADS
ret = fcntl(fd, (code & LOCK_NB) ? F_SETLK : F_SETLKW, &l);
Py_END_ALLOW_THREADS
} while (ret == -1 && errno == EINTR && !(async_err = PyErr_CheckSignals()));
}
#endif /* HAVE_FLOCK */
if (ret < 0) {
return !async_err ? PyErr_SetFromErrno(PyExc_OSError) : NULL;
}
Py_RETURN_NONE;
}2.2.3 Master/Worker日志收集(Socket/Queue模式)
这种方式也是被官方主推的方式
Although logging is thread-safe, and logging to a single file from multiple threads in a single process is supported, logging to a single file from multiple processes is not supported, because there is no standard way to serialize access to a single file across multiple processes in Python. If you need to log to a single file from multiple processes, one way of doing this is to have all the processes log to a SocketHandler, and have a separate process which implements a socket server which reads from the socket and logs to file.(如果你需要将多个进程中的日志记录至单个文件,有一个方案是让所有进程都将日志记录至一个 SocketHandler,第二用一个实现了套接字服务器的单独进程一边从套接字中读取一边将日志记录至文件) (If you prefer, you can dedicate one thread in one of the existing processes to perform this function.) This section documents this approach in more detail and includes a working socket receiver which can be used as a starting point for you to adapt in your own applications.
Alternatively, you can use a Queue and a QueueHandler to send all logging events to one of the processes in your multi-process application. (你也可以使用 Queue 和 QueueHandler 将所有的日志**发送至你的多进程应用的一个进程中。)The following example script demonstrates how you can do this; in the example a separate listener process listens for events sent by other processes and logs them according to its own logging configuration. Although the example only demonstrates one way of doing it (for example, you may want to use a listener thread rather than a separate listener process – the implementation would be **ogous) it does allow for completely different logging configurations for the listener and the other processes in your application, and can be used as the basis for code meeting your own specific requirements:
看看QueueHandler的案例
import logging
import logging.config
import logging.handlers
from multiprocessing import Process, Queue
import random
import threading
import time
def logger_thread(q):
"""
单独的日志记录线程
"""
while True:
record = q.get()
if record is None:
break
# 获取record实例中的logger
logger = logging.getLogger(record.name)
# 调用logger的handle方法处理
logger.handle(record)
def worker_process(q):
# 日志写入进程
qh = logging.handlers.QueueHandler(q)
root = logging.getLogger()
root.setLevel(logging.DEBUG)
# 绑定QueueHandler到logger
root.addHandler(qh)
levels = [logging.DEBUG, logging.INFO, logging.WARNING, logging.ERROR,
logging.CRITICAL]
loggers = ['foo', 'foo.bar', 'foo.bar.baz',
'spam', 'spam.ham', 'spam.ham.eggs']
for i in range(100):
lvl = random.choice(levels)
logger = logging.getLogger(random.choice(loggers))
logger.log(lvl, 'Message no. %d', i)
if __name__ == '__main__':
q = Queue()
# 省略一大推配置
workers = []
# 多进程写入日志到Queue
for i in range(5):
wp = Process(target=worker_process, name='worker %d' % (i + 1), args=(q,))
workers.append(wp)
wp.start()
logging.config.dictConfig(d)
# 启动子线程负责日志收集写入
lp = threading.Thread(target=logger_thread, args=(q,))
lp.start()
# At this point, the main process could do some useful work of its own
# Once it's done that, it can wait for the workers to terminate…
for wp in workers:
wp.join()
# And now tell the logging thread to finish up, too
q.put(None)
lp.join()
看看SocketHandler的案例
# 发送端
import logging, logging.handlers
rootLogger = logging.getLogger('')
rootLogger.setLevel(logging.DEBUG)
# 指定ip、端口
socketHandler = logging.handlers.SocketHandler('localhost',
logging.handlers.DEFAULT_TCP_LOGGING_PORT)
# don't bother with a formatter, since a socket handler sends the event as
# an unformatted pickle
rootLogger.addHandler(socketHandler)
# Now, we can log to the root logger, or any other logger. First the root…
logging.info('Jackdaws love my big sphinx of quartz.')
# Now, define a couple of other loggers which might represent areas in your
# application:
logger1 = logging.getLogger('myapp.area1')
logger2 = logging.getLogger('myapp.area2')
logger1.debug('Quick zephyrs blow, vexing daft Jim.')
logger1.info('How quickly daft jumping zebras vex.')
logger2.warning('Jail zesty vixen who grabbed pay from quack.')
logger2.error('The five boxing wizards jump quickly.')
# 接收端
import pickle
import logging
import logging.handlers
import socketserver
import struct
class LogRecordStreamHandler(socketserver.StreamRequestHandler):
"""Handler for a streaming logging request.
This basically logs the record using whatever logging policy is
configured locally.
"""
def handle(self):
"""
Handle multiple requests – each expected to be a 4-byte length,
followed by the LogRecord in pickle format. Logs the record
according to whatever policy is configured locally.
"""
while True:
# 接收数据的流程
chunk = self.connection.recv(4)
if len(chunk) < 4:
break
slen = struct.unpack('>L', chunk)[0]
chunk = self.connection.recv(slen)
while len(chunk) < slen:
chunk = chunk + self.connection.recv(slen – len(chunk))
obj = self.unPickle(chunk)
# 生成LodRecord实例,调用handleLogRecord处理
record = logging.makeLogRecord(obj)
self.handleLogRecord(record)
def unPickle(self, data):
return pickle.loads(data)
def handleLogRecord(self, record):
# if a name is specified, we use the named logger rather than the one
# implied by the record.
if self.server.logname is not None:
name = self.server.logname
else:
name = record.name
logger = logging.getLogger(name)
# N.B. EVERY record gets logged. This is because Logger.handle
# is normally called AFTER logger-level filtering. If you want
# to do filtering, do it at the client end to save wasting
# cycles and network bandwidth!
logger.handle(record)
class LogRecordSocketReceiver(socketserver.ThreadingTCPServer):
"""
Simple TCP socket-based logging receiver suitable for testing.
"""
allow_reuse_address = True
def __init__(self, host='localhost',
port=logging.handlers.DEFAULT_TCP_LOGGING_PORT,
handler=LogRecordStreamHandler):
socketserver.ThreadingTCPServer.__init__(self, (host, port), handler)
self.abort = 0
self.timeout = 1
self.logname = None
def serve_until_stopped(self):
import select
abort = 0
while not abort:
# select方法接收端口数据
rd, wr, ex = select.select([self.socket.fileno()],
[], [],
self.timeout)
if rd:
# 调用LogRecordStreamHandler的handle方法处理
self.handle_request()
abort = self.abort
def main():
logging.basicConfig(
format='%(relativeCreated)5d %(name)-15s %(levelname)-8s %(message)s')
tcpserver = LogRecordSocketReceiver()
print('About to start TCP server…')
tcpserver.serve_until_stopped()
if __name__ == '__main__':
main()
有关于 Master/Worker的方式就是上述的两种模式,日志写入的效率不受并发的影响,最终取决于写入线程。此外,对于日志的写入慢、阻塞问题,同样可以使用QueueHandlers以及其扩展的QueueListener来处理。
作者:技术拆解官原文链接:https://juejin.cn/post/6945301448934719518
拓展知识:
原创文章,作者:九贤生活小编,如若转载,请注明出处:http://www.wangguangwei.com/11764.html
相关推荐
-
ie缓存位置-IE下载的网页怎么查看
本文目录1、IE下载的网页怎么查看?2、在电脑上如何找到缓存文件夹,谢谢?3、在线观看的视频缓存到IE之后怎么把视频下载下来啊?4、ie浏览器打开的文件保存路径?5、IE浏览器下载的文件保存位置在哪?1、IE下载的网页怎么查看?正常情况下,本地IE缓存位置:C:\Users\Administrator\AppData\Local\Microsoft\Windows\TemporaryInterne
-
5000组装机怎么样,超值更能满足需求的5000元组装机
在电脑市场恒久不变的5000元价位中,能否拥有一台性价比高且满足日常需求的组装机呢?下面为您解答六个问题。 配置怎么样? 这款5000元组装机的配置并不低,CPU为英特尔芯片E51…
-
华硕天选官方网站(华硕官方网站查询)
华硕天选官方网站(华硕官方网站查询) 老铁们好啊,今天小编给大家分享下我们在使用电脑过程中会遇到的一些问题故障该如何处理,热门电脑游戏需求配置,电脑使用的一些小技巧 大机箱和小机箱…
-
901机箱用什么主板(x99主板用什么机箱)
901机箱用什么主板(x99主板用什么机箱) 老铁们好啊,今天小编给大家分享下在使用电脑和笔记本电脑过程中会遇到的一些问题故障该如何处理,手机使用的一些小技巧 神舟战神笔记本和华硕…
-
amdfx8350有集成显卡吗
amdfx8350有集成显卡吗 老铁们好啊,今天小编给大家分享下我们在使用电脑过程中会遇到的一些问题故障该如何处理,热门电脑游戏需求配置,电脑使用的一些小技巧 amd速龙iix47…
-
r51400内存兼容(R51400 3200内存)
r51400内存兼容(R51400 3200内存) 老铁们好啊,今天小编给大家分享下我们在使用电脑过程中会遇到的一些问题故障该如何处理,热门电脑游戏需求配置,电脑使用的一些小技巧 …
-
8000元的组装电脑主机(怎么组装电脑主机视频)
选购电脑配件的建议 想要组装一台可以满足日常使用和轻度游戏需要的电脑主机,预算约8000元左右的话,需要先确定好所需要的组件,以及它们的价格范围,这样才能在不浪费钱的情况下,选购到…
-
联想笔记本加内存条图解(联想笔记本充不了电怎么回事)
很多朋友对于联想笔记本加内存条图解(联想笔记本充不了电怎么回事)和联想笔记本加内存条图解(联想笔记本充不了电怎么回事)不太懂,今天就由小编来为大家分享,希望可以帮助到大家,下面一起来看看吧!联想修笔记本预约|增加ThinkPad内存步骤ThinkPa
-
轻薄笔记本论坛(轻薄笔记本显卡天梯图)
轻薄笔记本论坛(轻薄笔记本显卡天梯图) 老铁们好啊,今天小编给大家分享下我们在使用电脑过程中会遇到的一些问题故障该如何处理,热门电脑游戏需求配置,电脑使用的一些小技巧 Win7的内…
-
fx8300配gtx970够不够用,fx8300和gtx970搭配如何
fx8300和gtx970搭配会有瓶颈吗? 瓶颈情况取决于使用人的需求和游戏类型。对于一些需要大量CPU处理的游戏,如《使命召唤18》和《战地4》,fx8300可能会成为瓶颈。但对…