
前沿拓展:
kb3189866
下载 KB3189866 **更新包,试试!
我用的是VM虚拟机,**作系统是RedHat7.9的系统进行JDK和Hadoop的安装实施,
本过程只是作测试和学习参考用。
1、添加hadoop新用户
useradd -m hadoop -s /bin/bash # 添加hadoop用户
passwd hadoop # 配置hadoop用户的密码
vi /etc/sudoers #编辑配置文件 在root后一行加入 hadoop ALL=(ALL) ALL ,为hadoop添加管理员权限
2、配置免密登录(root)用户**作
ssh-keygen -t rsa # 会有提示,都按回车就OK
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys # 加入授权
chmod 0600 ~/.ssh/authorized_keys #添加权限
配置完成后,执行ssh hadoop(主机名)命令可以不用输入密码即可登录为配置成功。
如查发现生成ssh-keygen报错,这是没有安装openssh造成的,用yum安装即可。
[root@hadoop dfs]# rpm -qa |grep openssh
openssh-server-7.4p1-21.el7.x86_64
openssh-clients-7.4p1-21.el7.x86_64
openssh-7.4p1-21.el7.x86_64
3、配置JDK环境
下载JDK的安装包之后,将jdk安装到/usr/local/jdk 这个目录。
tar -zxvf /home/hadoop/download/jdk-8u212-linux-x64.tar.gz -C /usr/local/jdk/
添加环境变量
vi /etc/profile # 打开环境变量配置文件,添加下面的配置
# java环境变量配置
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
# 配置完成后 执行下面命令是配置生效
source /etc/profile
顺便把HADOOP_HOME的环境变量也一起添加了
# hadoop环境变量配置
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$JAVA_HOME/**in:$PATH
[root@hadoop download]# cat /etc/profile
unset i
unset -f pathmunge
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_212
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.3
export PATH=$HADOOP_HOME/bin:$PATH
export PATH=$HADOOP_HOME/**in:$PATH
java环境是否配置成功,我们执行java -version 可以看到java相关的信息
[root@hadoop download]# java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
4、安装配置Hadoop
Hadoop NameNode格式化及运行测试,接下来对hadoop进行一些配置,使其能以伪分布式的方式运行。进入到hadoop的配置文件所在的目录
cd /usr/local/hadoop/etc/hadoop配置hadoop-env.sh
在该文件内配置JAVA_HOME 所示:
vi /usr/local/hadoop/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
###
# Generic settings for HADOOP
###
# Technically, the only required environment variable is JAVA_HOME.
# All others are optional. However, the defaults are probably not
# preferred. Many sites configure these options outside of Hadoop,
# such as in /etc/profile.d
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_212
# Location of Hadoop. By default, Hadoop will attempt to determine
# this location based upon its execution path.
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.3
JAVA_HOME设置为我们自己的jdk安装路径即可
1、配置hdfs-site.xml
hdfs-site.xml的内容改成下面的配置。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop_data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop_data/dfs/data</value>
</property>
</configuration>dfs.replication # 为文件保存副本的数量
dfs.namenode.name.dir # 为hadoop namenode数据目录,改成自己需要的目录(不存在需新建)
dfs.datanode.data.dir # 为hadoop datanode数据目录,改成自己需要的目录(不存在需新建)
1、配置core-site.xml
core-site.xml的内容改成下面的配置。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop_data</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
</configuration>hadoop.tmp.dir # hadoop 缓存目录,更改为自己的目录(不存在需创建)
fs.defaultFS # hadoop fs **端口配置
mkdir /home/hadoop_data/dfs/name
mkdir /home/hadoop_data/dfs/data
cd /home/hadoop_data/
chown -R hadoop:hadoop dfs && chmod -R 777 dfs
如果只需要HDFS,配置就完成,如果需要用到Yarn,还需要做yarn相关的配置。
1、配置mapred-site.xml
mapred-site.xml的内容改成下面的配置。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
1、配置yarn-site.xml
yarn-site.xml的内容改成下面的配置。
<configuration>
<!– Site specific YARN configuration properties –>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Hadoop格式化及启动
现在hadoop基础配置已经完成了,需要对Hadoop的namenode进行格式化,第二启动hadoop dfs服务。
1、NameNode格式化我们跳转到hadoop的bin目录,并执行格式化命令
cd /usr/local/hadoop/bin
./hdfs namenode -format
执行结果如下图所示,当exit status 为0时,则为格式化成功。
此时我们的hadoop已经格式化成功了,接下来我们去启动我们hadoop。
进到hadoop下的**in目录
cd /usr/local/hadoop/**in
./start-dfs.sh # 启动HDFS
./start-yarn.sh # 启动YARN
执行./start-dfs.sh 如下图所示:
[hadoop@hadoop ~]$ stop-dfs.sh
Stopping namenodes on [hadoop]
Stopping datanodes
Stopping secondary namenodes [hadoop]
[hadoop@hadoop ~]$ start-dfs.sh
Starting namenodes on [hadoop]
Starting datanodes
Starting secondary namenodes [hadoop]
[hadoop@hadoop ~]$ jps
48336 Jps
48002 DataNode
48210 SecondaryNameNode
46725 NodeManager
46621 ResourceManager
47886 NameNode
[hadoop@hadoop ~]$
还可以看日志看是不启动报错
[hadoop@hadoop logs]$ ls -rlt
total 2528
-rw-rw-r–. 1 hadoop hadoop 0 Mar 17 23:15 SecurityAuth-hadoop.audit
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 09:37 hadoop-hadoop-datanode-hadoop.out.5
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 09:38 hadoop-hadoop-secondarynamenode-hadoop.out.5
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:04 hadoop-hadoop-namenode-hadoop.out.5
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:04 hadoop-hadoop-datanode-hadoop.out.4
-rw-rw-r–. 1 hadoop hadoop 4124 Mar 18 10:05 hadoop-hadoop-secondarynamenode-hadoop.out.4
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:06 hadoop-hadoop-namenode-hadoop.out.4
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:06 hadoop-hadoop-datanode-hadoop.out.3
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:31 hadoop-hadoop-namenode-hadoop.out.3
-rw-rw-r–. 1 hadoop hadoop 121390 Mar 18 10:50 hadoop-hadoop-secondarynamenode-hadoop.out.3
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:51 hadoop-hadoop-namenode-hadoop.out.2
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:52 hadoop-hadoop-datanode-hadoop.out.2
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:52 hadoop-hadoop-secondarynamenode-hadoop.out.2
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:53 hadoop-hadoop-datanode-hadoop.out.1
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:54 hadoop-hadoop-secondarynamenode-hadoop.out.1
-rw-rw-r–. 1 hadoop hadoop 6151 Mar 18 10:55 hadoop-hadoop-namenode-hadoop.out.1
-rw-rw-r–. 1 hadoop hadoop 2215 Mar 18 14:42 hadoop-hadoop-resourcemanager-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 2199 Mar 18 14:43 hadoop-hadoop-nodemanager-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 41972 Mar 18 14:52 hadoop-hadoop-resourcemanager-hadoop.log
-rw-rw-r–. 1 hadoop hadoop 37935 Mar 18 15:42 hadoop-hadoop-nodemanager-hadoop.log
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 15:48 hadoop-hadoop-namenode-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 15:48 hadoop-hadoop-datanode-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 15:48 hadoop-hadoop-secondarynamenode-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 970190 Mar 18 15:48 hadoop-hadoop-datanode-hadoop.log
drwxr-xr-x. 2 hadoop hadoop 6 Mar 18 15:48 userlogs
-rw-rw-r–. 1 hadoop hadoop 572169 Mar 18 15:49 hadoop-hadoop-namenode-hadoop.log
-rw-rw-r–. 1 hadoop hadoop 656741 Mar 18 15:49 hadoop-hadoop-secondarynamenode-hadoop.log
[hadoop@hadoop logs]$ pwd
/usr/local/hadoop/hadoop-3.1.3/logs
[hadoop@hadoop logs]$ tail -20f hadoop-hadoop-namenode-hadoop.log
2022-03-18 15:48:39,521 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* registerDatanode: from DatanodeRegistration(192.168.10.248:9866, datanodeUuid=daafd206-fdfe-44cc-a1fc-8ac1279c5cda, infoPort=9864, infoSecurePort=0, ipcPort=9867, storageInfo=lv=-57;cid=CID-f921bab0-7c73-44ef-bc61-ea81d176ec82;nsid=311459717;c=1647534325420) storage daafd206-fdfe-44cc-a1fc-8ac1279c5cda
2022-03-18 15:48:39,523 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/192.168.10.248:9866
2022-03-18 15:48:39,523 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockReportLeaseManager: Registered DN daafd206-fdfe-44cc-a1fc-8ac1279c5cda (192.168.10.248:9866).
2022-03-18 15:48:39,889 INFO org.apache.hadoop.hdfs.server.blockmanagement.DatanodeDescriptor: Adding new storage ID DS-6dd0b7dc-1fd0-488c-924b-76de306ac2cb for DN 192.168.10.248:9866
2022-03-18 15:48:40,062 INFO BlockStateChange: BLOCK* processReport 0xf15bae747aec7666: Processing first storage report for DS-6dd0b7dc-1fd0-488c-924b-76de306ac2cb from datanode daafd206-fdfe-44cc-a1fc-8ac1279c5cda
2022-03-18 15:48:40,065 INFO BlockStateChange: BLOCK* processReport 0xf15bae747aec7666: from storage DS-6dd0b7dc-1fd0-488c-924b-76de306ac2cb node DatanodeRegistration(192.168.10.248:9866, datanodeUuid=daafd206-fdfe-44cc-a1fc-8ac1279c5cda, infoPort=9864, infoSecurePort=0, ipcPort=9867, storageInfo=lv=-57;cid=CID-f921bab0-7c73-44ef-bc61-ea81d176ec82;nsid=311459717;c=1647534325420), blocks: 0, hasStaleStorage: false, processing time: 3 msecs, invalidatedBlocks: 0
2022-03-18 15:49:44,972 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Roll Edit Log from 192.168.10.248
2022-03-18 15:49:44,972 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Rolling edit logs
2022-03-18 15:49:44,973 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Ending log segment 85, 85
2022-03-18 15:49:44,973 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Number of transactions: 2 Total time for transactions(ms): 2 Number of transactions batched in Syncs: 84 Number of syncs: 2 SyncTimes(ms): 130
2022-03-18 15:49:44,988 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Number of transactions: 2 Total time for transactions(ms): 2 Number of transactions batched in Syncs: 84 Number of syncs: 3 SyncTimes(ms): 144
2022-03-18 15:49:44,990 INFO org.apache.hadoop.hdfs.server.namenode.FileJournalManager: Finalizing edits file /home/hadoop_data/dfs/name/current/edits_inprogress_0000000000000000085 -> /home/hadoop_data/dfs/name/current/edits_0000000000000000085-0000000000000000086
2022-03-18 15:49:44,992 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Starting log segment at 87
2022-03-18 15:49:45,514 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Sending fileName: /home/hadoop_data/dfs/name/current/fsimage_0000000000000000083, fileSize: 533. Sent total: 533 bytes. Size of last segment intended to send: -1 bytes.
2022-03-18 15:49:45,641 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Sending fileName: /home/hadoop_data/dfs/name/current/edits_0000000000000000084-0000000000000000084, fileSize: 1048576. Sent total: 1048576 bytes. Size of last segment intended to send: -1 bytes.
2022-03-18 15:49:45,744 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Sending fileName: /home/hadoop_data/dfs/name/current/edits_0000000000000000085-0000000000000000086, fileSize: 42. Sent total: 42 bytes. Size of last segment intended to send: -1 bytes.
2022-03-18 15:49:46,668 INFO org.apache.hadoop.hdfs.server.common.Util: Combined time for file download and fsync to all disks took 0.00s. The file download took 0.00s at 0.00 KB/s. Synchronous (fsync) write to disk of /home/hadoop_data/dfs/name/current/fsimage.ckpt_0000000000000000086 took 0.00s.
2022-03-18 15:49:46,668 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000086 size 533 bytes.
2022-03-18 15:49:46,684 INFO org.apache.hadoop.hdfs.server.namenode.NNStorageRetentionManager: Going to retain 2 images with txid >= 83
2022-03-18 15:49:46,684 INFO org.apache.hadoop.hdfs.server.namenode.NNStorageRetentionManager: Purging old image FSImageFile(file=/home/hadoop_data/dfs/name/current/fsimage_0000000000000000081, cpktTxId=0000000000000000081)
这就是namenode启动成功,如查格式化两次就会出现datanode启动不成功,这是clusterID两次不致造成的,可以进入
-rw-rw-r–. 1 hadoop hadoop 229 Mar 18 15:48 VERSION
drwx——. 4 hadoop hadoop 54 Mar 18 15:48 BP-301391941-192.168.10.248-1647534325420
[root@hadoop current]# cat VERSION
#Fri Mar 18 15:48:38 CST 2022
storageID=DS-6dd0b7dc-1fd0-488c-924b-76de306ac2cb
clusterID=CID-f921bab0-7c73-44ef-bc61-ea81d176ec82
cTime=0
datanodeUuid=daafd206-fdfe-44cc-a1fc-8ac1279c5cda
storageType=DATA_NODE
layoutVersion=-57
[root@hadoop current]# pwd
/home/hadoop_data/dfs/data/current
修改clusterID和namenode节点的clusterID一样后,在重启hadoop服务
现在伪分布式hadoop集群已经部署成功了,如果启动hadoop的时候遇到了问题,可以查看对应的log文件查看是由什么问题引起的。一般的问题如,未设置JAVA_HOME hadoopdata目录不存在,或者无权限等等。
现要在可以进入hadoop组件hdfs的UI界面:


现要在可以进入hadoop组件yarn的UI界面:
可能安装过成会遇到各样的问题,可是查看日志和搜索或是去官网站都可以找到解决的**,我只是把做的过程记录出来了,以备后需。
拓展知识:
kb3189866
有的机器升级不仅仅一次不成功,有时候反复升级都是这样,这样的情况我在升级补丁的时候也遇到过!比如:升级W10周年版本的14393(kb3189866)的时候更新到45%就卡住了,没办法进一步的往下进行,最后还是在论坛里找到升级的下载包解决了!
前沿拓展:
kb3189866
下载 KB3189866 **更新包,试试!
我用的是VM虚拟机,**作系统是RedHat7.9的系统进行JDK和Hadoop的安装实施,
本过程只是作测试和学习参考用。
1、添加hadoop新用户
useradd -m hadoop -s /bin/bash # 添加hadoop用户
passwd hadoop # 配置hadoop用户的密码
vi /etc/sudoers #编辑配置文件 在root后一行加入 hadoop ALL=(ALL) ALL ,为hadoop添加管理员权限
2、配置免密登录(root)用户**作
ssh-keygen -t rsa # 会有提示,都按回车就OK
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys # 加入授权
chmod 0600 ~/.ssh/authorized_keys #添加权限
配置完成后,执行ssh hadoop(主机名)命令可以不用输入密码即可登录为配置成功。
如查发现生成ssh-keygen报错,这是没有安装openssh造成的,用yum安装即可。
[root@hadoop dfs]# rpm -qa |grep openssh
openssh-server-7.4p1-21.el7.x86_64
openssh-clients-7.4p1-21.el7.x86_64
openssh-7.4p1-21.el7.x86_64
3、配置JDK环境
下载JDK的安装包之后,将jdk安装到/usr/local/jdk 这个目录。
tar -zxvf /home/hadoop/download/jdk-8u212-linux-x64.tar.gz -C /usr/local/jdk/
添加环境变量
vi /etc/profile # 打开环境变量配置文件,添加下面的配置
# java环境变量配置
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
# 配置完成后 执行下面命令是配置生效
source /etc/profile
顺便把HADOOP_HOME的环境变量也一起添加了
# hadoop环境变量配置
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$JAVA_HOME/**in:$PATH
[root@hadoop download]# cat /etc/profile
unset i
unset -f pathmunge
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_212
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.3
export PATH=$HADOOP_HOME/bin:$PATH
export PATH=$HADOOP_HOME/**in:$PATH
java环境是否配置成功,我们执行java -version 可以看到java相关的信息
[root@hadoop download]# java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
4、安装配置Hadoop
Hadoop NameNode格式化及运行测试,接下来对hadoop进行一些配置,使其能以伪分布式的方式运行。进入到hadoop的配置文件所在的目录
cd /usr/local/hadoop/etc/hadoop配置hadoop-env.sh
在该文件内配置JAVA_HOME 所示:
vi /usr/local/hadoop/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
###
# Generic settings for HADOOP
###
# Technically, the only required environment variable is JAVA_HOME.
# All others are optional. However, the defaults are probably not
# preferred. Many sites configure these options outside of Hadoop,
# such as in /etc/profile.d
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_212
# Location of Hadoop. By default, Hadoop will attempt to determine
# this location based upon its execution path.
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.3
JAVA_HOME设置为我们自己的jdk安装路径即可
1、配置hdfs-site.xml
hdfs-site.xml的内容改成下面的配置。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop_data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop_data/dfs/data</value>
</property>
</configuration>dfs.replication # 为文件保存副本的数量
dfs.namenode.name.dir # 为hadoop namenode数据目录,改成自己需要的目录(不存在需新建)
dfs.datanode.data.dir # 为hadoop datanode数据目录,改成自己需要的目录(不存在需新建)
1、配置core-site.xml
core-site.xml的内容改成下面的配置。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop_data</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
</configuration>hadoop.tmp.dir # hadoop 缓存目录,更改为自己的目录(不存在需创建)
fs.defaultFS # hadoop fs **端口配置
mkdir /home/hadoop_data/dfs/name
mkdir /home/hadoop_data/dfs/data
cd /home/hadoop_data/
chown -R hadoop:hadoop dfs && chmod -R 777 dfs
如果只需要HDFS,配置就完成,如果需要用到Yarn,还需要做yarn相关的配置。
1、配置mapred-site.xml
mapred-site.xml的内容改成下面的配置。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
1、配置yarn-site.xml
yarn-site.xml的内容改成下面的配置。
<configuration>
<!– Site specific YARN configuration properties –>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Hadoop格式化及启动
现在hadoop基础配置已经完成了,需要对Hadoop的namenode进行格式化,第二启动hadoop dfs服务。
1、NameNode格式化我们跳转到hadoop的bin目录,并执行格式化命令
cd /usr/local/hadoop/bin
./hdfs namenode -format
执行结果如下图所示,当exit status 为0时,则为格式化成功。
此时我们的hadoop已经格式化成功了,接下来我们去启动我们hadoop。
进到hadoop下的**in目录
cd /usr/local/hadoop/**in
./start-dfs.sh # 启动HDFS
./start-yarn.sh # 启动YARN
执行./start-dfs.sh 如下图所示:
[hadoop@hadoop ~]$ stop-dfs.sh
Stopping namenodes on [hadoop]
Stopping datanodes
Stopping secondary namenodes [hadoop]
[hadoop@hadoop ~]$ start-dfs.sh
Starting namenodes on [hadoop]
Starting datanodes
Starting secondary namenodes [hadoop]
[hadoop@hadoop ~]$ jps
48336 Jps
48002 DataNode
48210 SecondaryNameNode
46725 NodeManager
46621 ResourceManager
47886 NameNode
[hadoop@hadoop ~]$
还可以看日志看是不启动报错
[hadoop@hadoop logs]$ ls -rlt
total 2528
-rw-rw-r–. 1 hadoop hadoop 0 Mar 17 23:15 SecurityAuth-hadoop.audit
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 09:37 hadoop-hadoop-datanode-hadoop.out.5
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 09:38 hadoop-hadoop-secondarynamenode-hadoop.out.5
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:04 hadoop-hadoop-namenode-hadoop.out.5
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:04 hadoop-hadoop-datanode-hadoop.out.4
-rw-rw-r–. 1 hadoop hadoop 4124 Mar 18 10:05 hadoop-hadoop-secondarynamenode-hadoop.out.4
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:06 hadoop-hadoop-namenode-hadoop.out.4
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:06 hadoop-hadoop-datanode-hadoop.out.3
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:31 hadoop-hadoop-namenode-hadoop.out.3
-rw-rw-r–. 1 hadoop hadoop 121390 Mar 18 10:50 hadoop-hadoop-secondarynamenode-hadoop.out.3
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:51 hadoop-hadoop-namenode-hadoop.out.2
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:52 hadoop-hadoop-datanode-hadoop.out.2
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:52 hadoop-hadoop-secondarynamenode-hadoop.out.2
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:53 hadoop-hadoop-datanode-hadoop.out.1
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:54 hadoop-hadoop-secondarynamenode-hadoop.out.1
-rw-rw-r–. 1 hadoop hadoop 6151 Mar 18 10:55 hadoop-hadoop-namenode-hadoop.out.1
-rw-rw-r–. 1 hadoop hadoop 2215 Mar 18 14:42 hadoop-hadoop-resourcemanager-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 2199 Mar 18 14:43 hadoop-hadoop-nodemanager-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 41972 Mar 18 14:52 hadoop-hadoop-resourcemanager-hadoop.log
-rw-rw-r–. 1 hadoop hadoop 37935 Mar 18 15:42 hadoop-hadoop-nodemanager-hadoop.log
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 15:48 hadoop-hadoop-namenode-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 15:48 hadoop-hadoop-datanode-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 15:48 hadoop-hadoop-secondarynamenode-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 970190 Mar 18 15:48 hadoop-hadoop-datanode-hadoop.log
drwxr-xr-x. 2 hadoop hadoop 6 Mar 18 15:48 userlogs
-rw-rw-r–. 1 hadoop hadoop 572169 Mar 18 15:49 hadoop-hadoop-namenode-hadoop.log
-rw-rw-r–. 1 hadoop hadoop 656741 Mar 18 15:49 hadoop-hadoop-secondarynamenode-hadoop.log
[hadoop@hadoop logs]$ pwd
/usr/local/hadoop/hadoop-3.1.3/logs
[hadoop@hadoop logs]$ tail -20f hadoop-hadoop-namenode-hadoop.log
2022-03-18 15:48:39,521 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* registerDatanode: from DatanodeRegistration(192.168.10.248:9866, datanodeUuid=daafd206-fdfe-44cc-a1fc-8ac1279c5cda, infoPort=9864, infoSecurePort=0, ipcPort=9867, storageInfo=lv=-57;cid=CID-f921bab0-7c73-44ef-bc61-ea81d176ec82;nsid=311459717;c=1647534325420) storage daafd206-fdfe-44cc-a1fc-8ac1279c5cda
2022-03-18 15:48:39,523 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/192.168.10.248:9866
2022-03-18 15:48:39,523 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockReportLeaseManager: Registered DN daafd206-fdfe-44cc-a1fc-8ac1279c5cda (192.168.10.248:9866).
2022-03-18 15:48:39,889 INFO org.apache.hadoop.hdfs.server.blockmanagement.DatanodeDescriptor: Adding new storage ID DS-6dd0b7dc-1fd0-488c-924b-76de306ac2cb for DN 192.168.10.248:9866
2022-03-18 15:48:40,062 INFO BlockStateChange: BLOCK* processReport 0xf15bae747aec7666: Processing first storage report for DS-6dd0b7dc-1fd0-488c-924b-76de306ac2cb from datanode daafd206-fdfe-44cc-a1fc-8ac1279c5cda
2022-03-18 15:48:40,065 INFO BlockStateChange: BLOCK* processReport 0xf15bae747aec7666: from storage DS-6dd0b7dc-1fd0-488c-924b-76de306ac2cb node DatanodeRegistration(192.168.10.248:9866, datanodeUuid=daafd206-fdfe-44cc-a1fc-8ac1279c5cda, infoPort=9864, infoSecurePort=0, ipcPort=9867, storageInfo=lv=-57;cid=CID-f921bab0-7c73-44ef-bc61-ea81d176ec82;nsid=311459717;c=1647534325420), blocks: 0, hasStaleStorage: false, processing time: 3 msecs, invalidatedBlocks: 0
2022-03-18 15:49:44,972 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Roll Edit Log from 192.168.10.248
2022-03-18 15:49:44,972 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Rolling edit logs
2022-03-18 15:49:44,973 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Ending log segment 85, 85
2022-03-18 15:49:44,973 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Number of transactions: 2 Total time for transactions(ms): 2 Number of transactions batched in Syncs: 84 Number of syncs: 2 SyncTimes(ms): 130
2022-03-18 15:49:44,988 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Number of transactions: 2 Total time for transactions(ms): 2 Number of transactions batched in Syncs: 84 Number of syncs: 3 SyncTimes(ms): 144
2022-03-18 15:49:44,990 INFO org.apache.hadoop.hdfs.server.namenode.FileJournalManager: Finalizing edits file /home/hadoop_data/dfs/name/current/edits_inprogress_0000000000000000085 -> /home/hadoop_data/dfs/name/current/edits_0000000000000000085-0000000000000000086
2022-03-18 15:49:44,992 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Starting log segment at 87
2022-03-18 15:49:45,514 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Sending fileName: /home/hadoop_data/dfs/name/current/fsimage_0000000000000000083, fileSize: 533. Sent total: 533 bytes. Size of last segment intended to send: -1 bytes.
2022-03-18 15:49:45,641 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Sending fileName: /home/hadoop_data/dfs/name/current/edits_0000000000000000084-0000000000000000084, fileSize: 1048576. Sent total: 1048576 bytes. Size of last segment intended to send: -1 bytes.
2022-03-18 15:49:45,744 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Sending fileName: /home/hadoop_data/dfs/name/current/edits_0000000000000000085-0000000000000000086, fileSize: 42. Sent total: 42 bytes. Size of last segment intended to send: -1 bytes.
2022-03-18 15:49:46,668 INFO org.apache.hadoop.hdfs.server.common.Util: Combined time for file download and fsync to all disks took 0.00s. The file download took 0.00s at 0.00 KB/s. Synchronous (fsync) write to disk of /home/hadoop_data/dfs/name/current/fsimage.ckpt_0000000000000000086 took 0.00s.
2022-03-18 15:49:46,668 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000086 size 533 bytes.
2022-03-18 15:49:46,684 INFO org.apache.hadoop.hdfs.server.namenode.NNStorageRetentionManager: Going to retain 2 images with txid >= 83
2022-03-18 15:49:46,684 INFO org.apache.hadoop.hdfs.server.namenode.NNStorageRetentionManager: Purging old image FSImageFile(file=/home/hadoop_data/dfs/name/current/fsimage_0000000000000000081, cpktTxId=0000000000000000081)
这就是namenode启动成功,如查格式化两次就会出现datanode启动不成功,这是clusterID两次不致造成的,可以进入
-rw-rw-r–. 1 hadoop hadoop 229 Mar 18 15:48 VERSION
drwx——. 4 hadoop hadoop 54 Mar 18 15:48 BP-301391941-192.168.10.248-1647534325420
[root@hadoop current]# cat VERSION
#Fri Mar 18 15:48:38 CST 2022
storageID=DS-6dd0b7dc-1fd0-488c-924b-76de306ac2cb
clusterID=CID-f921bab0-7c73-44ef-bc61-ea81d176ec82
cTime=0
datanodeUuid=daafd206-fdfe-44cc-a1fc-8ac1279c5cda
storageType=DATA_NODE
layoutVersion=-57
[root@hadoop current]# pwd
/home/hadoop_data/dfs/data/current
修改clusterID和namenode节点的clusterID一样后,在重启hadoop服务
现在伪分布式hadoop集群已经部署成功了,如果启动hadoop的时候遇到了问题,可以查看对应的log文件查看是由什么问题引起的。一般的问题如,未设置JAVA_HOME hadoopdata目录不存在,或者无权限等等。
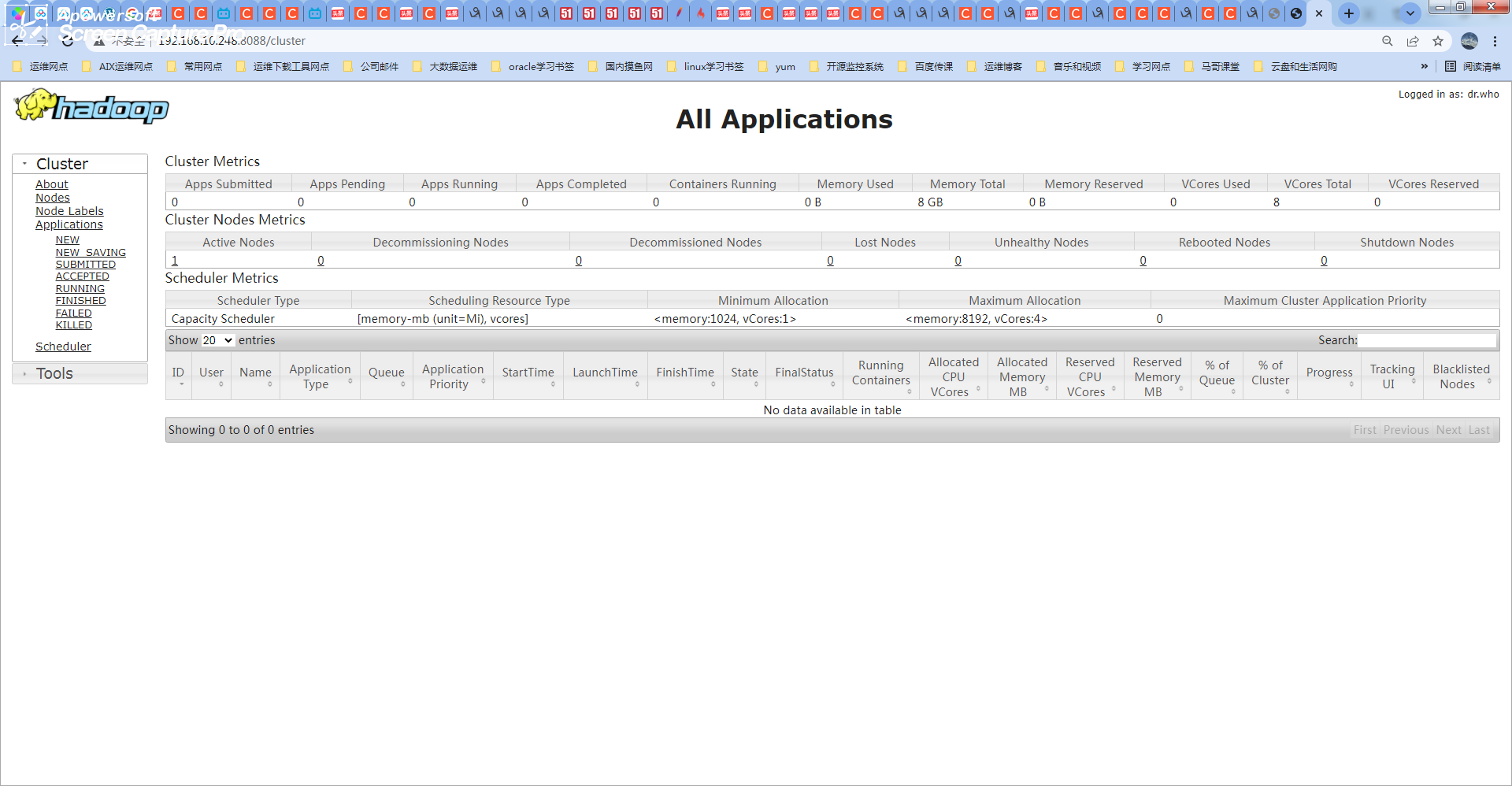
现要在可以进入hadoop组件hdfs的UI界面:
现要在可以进入hadoop组件yarn的UI界面:
可能安装过成会遇到各样的问题,可是查看日志和搜索或是去官网站都可以找到解决的**,我只是把做的过程记录出来了,以备后需。
拓展知识:
kb3189866
有的机器升级不仅仅一次不成功,有时候反复升级都是这样,这样的情况我在升级补丁的时候也遇到过!比如:升级W10周年版本的14393(kb3189866)的时候更新到45%就卡住了,没办法进一步的往下进行,最后还是在论坛里找到升级的下载包解决了!
前沿拓展:
kb3189866
下载 KB3189866 **更新包,试试!
我用的是VM虚拟机,**作系统是RedHat7.9的系统进行JDK和Hadoop的安装实施,
本过程只是作测试和学习参考用。
1、添加hadoop新用户
useradd -m hadoop -s /bin/bash # 添加hadoop用户
passwd hadoop # 配置hadoop用户的密码
vi /etc/sudoers #编辑配置文件 在root后一行加入 hadoop ALL=(ALL) ALL ,为hadoop添加管理员权限
2、配置免密登录(root)用户**作
ssh-keygen -t rsa # 会有提示,都按回车就OK
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys # 加入授权
chmod 0600 ~/.ssh/authorized_keys #添加权限
配置完成后,执行ssh hadoop(主机名)命令可以不用输入密码即可登录为配置成功。
如查发现生成ssh-keygen报错,这是没有安装openssh造成的,用yum安装即可。
[root@hadoop dfs]# rpm -qa |grep openssh
openssh-server-7.4p1-21.el7.x86_64
openssh-clients-7.4p1-21.el7.x86_64
openssh-7.4p1-21.el7.x86_64
3、配置JDK环境
下载JDK的安装包之后,将jdk安装到/usr/local/jdk 这个目录。
tar -zxvf /home/hadoop/download/jdk-8u212-linux-x64.tar.gz -C /usr/local/jdk/
添加环境变量
vi /etc/profile # 打开环境变量配置文件,添加下面的配置
# java环境变量配置
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
# 配置完成后 执行下面命令是配置生效
source /etc/profile
顺便把HADOOP_HOME的环境变量也一起添加了
# hadoop环境变量配置
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$JAVA_HOME/**in:$PATH
[root@hadoop download]# cat /etc/profile
unset i
unset -f pathmunge
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_212
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.3
export PATH=$HADOOP_HOME/bin:$PATH
export PATH=$HADOOP_HOME/**in:$PATH
java环境是否配置成功,我们执行java -version 可以看到java相关的信息
[root@hadoop download]# java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
4、安装配置Hadoop
Hadoop NameNode格式化及运行测试,接下来对hadoop进行一些配置,使其能以伪分布式的方式运行。进入到hadoop的配置文件所在的目录
cd /usr/local/hadoop/etc/hadoop配置hadoop-env.sh
在该文件内配置JAVA_HOME 所示:
vi /usr/local/hadoop/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
###
# Generic settings for HADOOP
###
# Technically, the only required environment variable is JAVA_HOME.
# All others are optional. However, the defaults are probably not
# preferred. Many sites configure these options outside of Hadoop,
# such as in /etc/profile.d
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_212
# Location of Hadoop. By default, Hadoop will attempt to determine
# this location based upon its execution path.
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.3
JAVA_HOME设置为我们自己的jdk安装路径即可
1、配置hdfs-site.xml
hdfs-site.xml的内容改成下面的配置。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop_data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop_data/dfs/data</value>
</property>
</configuration>dfs.replication # 为文件保存副本的数量
dfs.namenode.name.dir # 为hadoop namenode数据目录,改成自己需要的目录(不存在需新建)
dfs.datanode.data.dir # 为hadoop datanode数据目录,改成自己需要的目录(不存在需新建)
1、配置core-site.xml
core-site.xml的内容改成下面的配置。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop_data</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
</configuration>hadoop.tmp.dir # hadoop 缓存目录,更改为自己的目录(不存在需创建)
fs.defaultFS # hadoop fs **端口配置
mkdir /home/hadoop_data/dfs/name
mkdir /home/hadoop_data/dfs/data
cd /home/hadoop_data/
chown -R hadoop:hadoop dfs && chmod -R 777 dfs
如果只需要HDFS,配置就完成,如果需要用到Yarn,还需要做yarn相关的配置。
1、配置mapred-site.xml
mapred-site.xml的内容改成下面的配置。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
1、配置yarn-site.xml
yarn-site.xml的内容改成下面的配置。
<configuration>
<!– Site specific YARN configuration properties –>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Hadoop格式化及启动
现在hadoop基础配置已经完成了,需要对Hadoop的namenode进行格式化,第二启动hadoop dfs服务。
1、NameNode格式化我们跳转到hadoop的bin目录,并执行格式化命令
cd /usr/local/hadoop/bin
./hdfs namenode -format
执行结果如下图所示,当exit status 为0时,则为格式化成功。
此时我们的hadoop已经格式化成功了,接下来我们去启动我们hadoop。
进到hadoop下的**in目录
cd /usr/local/hadoop/**in
./start-dfs.sh # 启动HDFS
./start-yarn.sh # 启动YARN
执行./start-dfs.sh 如下图所示:
[hadoop@hadoop ~]$ stop-dfs.sh
Stopping namenodes on [hadoop]
Stopping datanodes
Stopping secondary namenodes [hadoop]
[hadoop@hadoop ~]$ start-dfs.sh
Starting namenodes on [hadoop]
Starting datanodes
Starting secondary namenodes [hadoop]
[hadoop@hadoop ~]$ jps
48336 Jps
48002 DataNode
48210 SecondaryNameNode
46725 NodeManager
46621 ResourceManager
47886 NameNode
[hadoop@hadoop ~]$
还可以看日志看是不启动报错
[hadoop@hadoop logs]$ ls -rlt
total 2528
-rw-rw-r–. 1 hadoop hadoop 0 Mar 17 23:15 SecurityAuth-hadoop.audit
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 09:37 hadoop-hadoop-datanode-hadoop.out.5
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 09:38 hadoop-hadoop-secondarynamenode-hadoop.out.5
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:04 hadoop-hadoop-namenode-hadoop.out.5
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:04 hadoop-hadoop-datanode-hadoop.out.4
-rw-rw-r–. 1 hadoop hadoop 4124 Mar 18 10:05 hadoop-hadoop-secondarynamenode-hadoop.out.4
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:06 hadoop-hadoop-namenode-hadoop.out.4
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:06 hadoop-hadoop-datanode-hadoop.out.3
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:31 hadoop-hadoop-namenode-hadoop.out.3
-rw-rw-r–. 1 hadoop hadoop 121390 Mar 18 10:50 hadoop-hadoop-secondarynamenode-hadoop.out.3
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:51 hadoop-hadoop-namenode-hadoop.out.2
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:52 hadoop-hadoop-datanode-hadoop.out.2
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:52 hadoop-hadoop-secondarynamenode-hadoop.out.2
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:53 hadoop-hadoop-datanode-hadoop.out.1
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:54 hadoop-hadoop-secondarynamenode-hadoop.out.1
-rw-rw-r–. 1 hadoop hadoop 6151 Mar 18 10:55 hadoop-hadoop-namenode-hadoop.out.1
-rw-rw-r–. 1 hadoop hadoop 2215 Mar 18 14:42 hadoop-hadoop-resourcemanager-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 2199 Mar 18 14:43 hadoop-hadoop-nodemanager-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 41972 Mar 18 14:52 hadoop-hadoop-resourcemanager-hadoop.log
-rw-rw-r–. 1 hadoop hadoop 37935 Mar 18 15:42 hadoop-hadoop-nodemanager-hadoop.log
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 15:48 hadoop-hadoop-namenode-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 15:48 hadoop-hadoop-datanode-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 15:48 hadoop-hadoop-secondarynamenode-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 970190 Mar 18 15:48 hadoop-hadoop-datanode-hadoop.log
drwxr-xr-x. 2 hadoop hadoop 6 Mar 18 15:48 userlogs
-rw-rw-r–. 1 hadoop hadoop 572169 Mar 18 15:49 hadoop-hadoop-namenode-hadoop.log
-rw-rw-r–. 1 hadoop hadoop 656741 Mar 18 15:49 hadoop-hadoop-secondarynamenode-hadoop.log
[hadoop@hadoop logs]$ pwd
/usr/local/hadoop/hadoop-3.1.3/logs
[hadoop@hadoop logs]$ tail -20f hadoop-hadoop-namenode-hadoop.log
2022-03-18 15:48:39,521 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* registerDatanode: from DatanodeRegistration(192.168.10.248:9866, datanodeUuid=daafd206-fdfe-44cc-a1fc-8ac1279c5cda, infoPort=9864, infoSecurePort=0, ipcPort=9867, storageInfo=lv=-57;cid=CID-f921bab0-7c73-44ef-bc61-ea81d176ec82;nsid=311459717;c=1647534325420) storage daafd206-fdfe-44cc-a1fc-8ac1279c5cda
2022-03-18 15:48:39,523 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/192.168.10.248:9866
2022-03-18 15:48:39,523 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockReportLeaseManager: Registered DN daafd206-fdfe-44cc-a1fc-8ac1279c5cda (192.168.10.248:9866).
2022-03-18 15:48:39,889 INFO org.apache.hadoop.hdfs.server.blockmanagement.DatanodeDescriptor: Adding new storage ID DS-6dd0b7dc-1fd0-488c-924b-76de306ac2cb for DN 192.168.10.248:9866
2022-03-18 15:48:40,062 INFO BlockStateChange: BLOCK* processReport 0xf15bae747aec7666: Processing first storage report for DS-6dd0b7dc-1fd0-488c-924b-76de306ac2cb from datanode daafd206-fdfe-44cc-a1fc-8ac1279c5cda
2022-03-18 15:48:40,065 INFO BlockStateChange: BLOCK* processReport 0xf15bae747aec7666: from storage DS-6dd0b7dc-1fd0-488c-924b-76de306ac2cb node DatanodeRegistration(192.168.10.248:9866, datanodeUuid=daafd206-fdfe-44cc-a1fc-8ac1279c5cda, infoPort=9864, infoSecurePort=0, ipcPort=9867, storageInfo=lv=-57;cid=CID-f921bab0-7c73-44ef-bc61-ea81d176ec82;nsid=311459717;c=1647534325420), blocks: 0, hasStaleStorage: false, processing time: 3 msecs, invalidatedBlocks: 0
2022-03-18 15:49:44,972 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Roll Edit Log from 192.168.10.248
2022-03-18 15:49:44,972 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Rolling edit logs
2022-03-18 15:49:44,973 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Ending log segment 85, 85
2022-03-18 15:49:44,973 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Number of transactions: 2 Total time for transactions(ms): 2 Number of transactions batched in Syncs: 84 Number of syncs: 2 SyncTimes(ms): 130
2022-03-18 15:49:44,988 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Number of transactions: 2 Total time for transactions(ms): 2 Number of transactions batched in Syncs: 84 Number of syncs: 3 SyncTimes(ms): 144
2022-03-18 15:49:44,990 INFO org.apache.hadoop.hdfs.server.namenode.FileJournalManager: Finalizing edits file /home/hadoop_data/dfs/name/current/edits_inprogress_0000000000000000085 -> /home/hadoop_data/dfs/name/current/edits_0000000000000000085-0000000000000000086
2022-03-18 15:49:44,992 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Starting log segment at 87
2022-03-18 15:49:45,514 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Sending fileName: /home/hadoop_data/dfs/name/current/fsimage_0000000000000000083, fileSize: 533. Sent total: 533 bytes. Size of last segment intended to send: -1 bytes.
2022-03-18 15:49:45,641 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Sending fileName: /home/hadoop_data/dfs/name/current/edits_0000000000000000084-0000000000000000084, fileSize: 1048576. Sent total: 1048576 bytes. Size of last segment intended to send: -1 bytes.
2022-03-18 15:49:45,744 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Sending fileName: /home/hadoop_data/dfs/name/current/edits_0000000000000000085-0000000000000000086, fileSize: 42. Sent total: 42 bytes. Size of last segment intended to send: -1 bytes.
2022-03-18 15:49:46,668 INFO org.apache.hadoop.hdfs.server.common.Util: Combined time for file download and fsync to all disks took 0.00s. The file download took 0.00s at 0.00 KB/s. Synchronous (fsync) write to disk of /home/hadoop_data/dfs/name/current/fsimage.ckpt_0000000000000000086 took 0.00s.
2022-03-18 15:49:46,668 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000086 size 533 bytes.
2022-03-18 15:49:46,684 INFO org.apache.hadoop.hdfs.server.namenode.NNStorageRetentionManager: Going to retain 2 images with txid >= 83
2022-03-18 15:49:46,684 INFO org.apache.hadoop.hdfs.server.namenode.NNStorageRetentionManager: Purging old image FSImageFile(file=/home/hadoop_data/dfs/name/current/fsimage_0000000000000000081, cpktTxId=0000000000000000081)
这就是namenode启动成功,如查格式化两次就会出现datanode启动不成功,这是clusterID两次不致造成的,可以进入
-rw-rw-r–. 1 hadoop hadoop 229 Mar 18 15:48 VERSION
drwx——. 4 hadoop hadoop 54 Mar 18 15:48 BP-301391941-192.168.10.248-1647534325420
[root@hadoop current]# cat VERSION
#Fri Mar 18 15:48:38 CST 2022
storageID=DS-6dd0b7dc-1fd0-488c-924b-76de306ac2cb
clusterID=CID-f921bab0-7c73-44ef-bc61-ea81d176ec82
cTime=0
datanodeUuid=daafd206-fdfe-44cc-a1fc-8ac1279c5cda
storageType=DATA_NODE
layoutVersion=-57
[root@hadoop current]# pwd
/home/hadoop_data/dfs/data/current
修改clusterID和namenode节点的clusterID一样后,在重启hadoop服务
现在伪分布式hadoop集群已经部署成功了,如果启动hadoop的时候遇到了问题,可以查看对应的log文件查看是由什么问题引起的。一般的问题如,未设置JAVA_HOME hadoopdata目录不存在,或者无权限等等。
现要在可以进入hadoop组件hdfs的UI界面:
现要在可以进入hadoop组件yarn的UI界面:
可能安装过成会遇到各样的问题,可是查看日志和搜索或是去官网站都可以找到解决的**,我只是把做的过程记录出来了,以备后需。
拓展知识:
kb3189866
有的机器升级不仅仅一次不成功,有时候反复升级都是这样,这样的情况我在升级补丁的时候也遇到过!比如:升级W10周年版本的14393(kb3189866)的时候更新到45%就卡住了,没办法进一步的往下进行,最后还是在论坛里找到升级的下载包解决了!
前沿拓展:
kb3189866
下载 KB3189866 **更新包,试试!
我用的是VM虚拟机,**作系统是RedHat7.9的系统进行JDK和Hadoop的安装实施,
本过程只是作测试和学习参考用。
1、添加hadoop新用户
useradd -m hadoop -s /bin/bash # 添加hadoop用户
passwd hadoop # 配置hadoop用户的密码
vi /etc/sudoers #编辑配置文件 在root后一行加入 hadoop ALL=(ALL) ALL ,为hadoop添加管理员权限
2、配置免密登录(root)用户**作
ssh-keygen -t rsa # 会有提示,都按回车就OK
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys # 加入授权
chmod 0600 ~/.ssh/authorized_keys #添加权限
配置完成后,执行ssh hadoop(主机名)命令可以不用输入密码即可登录为配置成功。
如查发现生成ssh-keygen报错,这是没有安装openssh造成的,用yum安装即可。
[root@hadoop dfs]# rpm -qa |grep openssh
openssh-server-7.4p1-21.el7.x86_64
openssh-clients-7.4p1-21.el7.x86_64
openssh-7.4p1-21.el7.x86_64
3、配置JDK环境
下载JDK的安装包之后,将jdk安装到/usr/local/jdk 这个目录。
tar -zxvf /home/hadoop/download/jdk-8u212-linux-x64.tar.gz -C /usr/local/jdk/
添加环境变量
vi /etc/profile # 打开环境变量配置文件,添加下面的配置
# java环境变量配置
export JAVA_HOME=/usr/local/jdk
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
# 配置完成后 执行下面命令是配置生效
source /etc/profile
顺便把HADOOP_HOME的环境变量也一起添加了
# hadoop环境变量配置
export HADOOP_HOME=/usr/local/hadoop
export PATH=$HADOOP_HOME/bin:$JAVA_HOME/**in:$PATH
[root@hadoop download]# cat /etc/profile
unset i
unset -f pathmunge
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_212
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.3
export PATH=$HADOOP_HOME/bin:$PATH
export PATH=$HADOOP_HOME/**in:$PATH
java环境是否配置成功,我们执行java -version 可以看到java相关的信息
[root@hadoop download]# java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
4、安装配置Hadoop
Hadoop NameNode格式化及运行测试,接下来对hadoop进行一些配置,使其能以伪分布式的方式运行。进入到hadoop的配置文件所在的目录
cd /usr/local/hadoop/etc/hadoop配置hadoop-env.sh
在该文件内配置JAVA_HOME 所示:
vi /usr/local/hadoop/hadoop-3.1.3/etc/hadoop/hadoop-env.sh
###
# Generic settings for HADOOP
###
# Technically, the only required environment variable is JAVA_HOME.
# All others are optional. However, the defaults are probably not
# preferred. Many sites configure these options outside of Hadoop,
# such as in /etc/profile.d
# The java implementation to use. By default, this environment
# variable is REQUIRED on ALL platforms except OS X!
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_212
# Location of Hadoop. By default, Hadoop will attempt to determine
# this location based upon its execution path.
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.1.3
JAVA_HOME设置为我们自己的jdk安装路径即可
1、配置hdfs-site.xml
hdfs-site.xml的内容改成下面的配置。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop_data/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop_data/dfs/data</value>
</property>
</configuration>dfs.replication # 为文件保存副本的数量
dfs.namenode.name.dir # 为hadoop namenode数据目录,改成自己需要的目录(不存在需新建)
dfs.datanode.data.dir # 为hadoop datanode数据目录,改成自己需要的目录(不存在需新建)
1、配置core-site.xml
core-site.xml的内容改成下面的配置。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop_data</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000</value>
</property>
</configuration>hadoop.tmp.dir # hadoop 缓存目录,更改为自己的目录(不存在需创建)
fs.defaultFS # hadoop fs **端口配置
mkdir /home/hadoop_data/dfs/name
mkdir /home/hadoop_data/dfs/data
cd /home/hadoop_data/
chown -R hadoop:hadoop dfs && chmod -R 777 dfs
如果只需要HDFS,配置就完成,如果需要用到Yarn,还需要做yarn相关的配置。
1、配置mapred-site.xml
mapred-site.xml的内容改成下面的配置。
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
1、配置yarn-site.xml
yarn-site.xml的内容改成下面的配置。
<configuration>
<!– Site specific YARN configuration properties –>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Hadoop格式化及启动
现在hadoop基础配置已经完成了,需要对Hadoop的namenode进行格式化,第二启动hadoop dfs服务。
1、NameNode格式化我们跳转到hadoop的bin目录,并执行格式化命令
cd /usr/local/hadoop/bin
./hdfs namenode -format
执行结果如下图所示,当exit status 为0时,则为格式化成功。
此时我们的hadoop已经格式化成功了,接下来我们去启动我们hadoop。
进到hadoop下的**in目录
cd /usr/local/hadoop/**in
./start-dfs.sh # 启动HDFS
./start-yarn.sh # 启动YARN
执行./start-dfs.sh 如下图所示:
[hadoop@hadoop ~]$ stop-dfs.sh
Stopping namenodes on [hadoop]
Stopping datanodes
Stopping secondary namenodes [hadoop]
[hadoop@hadoop ~]$ start-dfs.sh
Starting namenodes on [hadoop]
Starting datanodes
Starting secondary namenodes [hadoop]
[hadoop@hadoop ~]$ jps
48336 Jps
48002 DataNode
48210 SecondaryNameNode
46725 NodeManager
46621 ResourceManager
47886 NameNode
[hadoop@hadoop ~]$
还可以看日志看是不启动报错
[hadoop@hadoop logs]$ ls -rlt
total 2528
-rw-rw-r–. 1 hadoop hadoop 0 Mar 17 23:15 SecurityAuth-hadoop.audit
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 09:37 hadoop-hadoop-datanode-hadoop.out.5
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 09:38 hadoop-hadoop-secondarynamenode-hadoop.out.5
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:04 hadoop-hadoop-namenode-hadoop.out.5
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:04 hadoop-hadoop-datanode-hadoop.out.4
-rw-rw-r–. 1 hadoop hadoop 4124 Mar 18 10:05 hadoop-hadoop-secondarynamenode-hadoop.out.4
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:06 hadoop-hadoop-namenode-hadoop.out.4
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:06 hadoop-hadoop-datanode-hadoop.out.3
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:31 hadoop-hadoop-namenode-hadoop.out.3
-rw-rw-r–. 1 hadoop hadoop 121390 Mar 18 10:50 hadoop-hadoop-secondarynamenode-hadoop.out.3
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:51 hadoop-hadoop-namenode-hadoop.out.2
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:52 hadoop-hadoop-datanode-hadoop.out.2
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:52 hadoop-hadoop-secondarynamenode-hadoop.out.2
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:53 hadoop-hadoop-datanode-hadoop.out.1
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 10:54 hadoop-hadoop-secondarynamenode-hadoop.out.1
-rw-rw-r–. 1 hadoop hadoop 6151 Mar 18 10:55 hadoop-hadoop-namenode-hadoop.out.1
-rw-rw-r–. 1 hadoop hadoop 2215 Mar 18 14:42 hadoop-hadoop-resourcemanager-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 2199 Mar 18 14:43 hadoop-hadoop-nodemanager-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 41972 Mar 18 14:52 hadoop-hadoop-resourcemanager-hadoop.log
-rw-rw-r–. 1 hadoop hadoop 37935 Mar 18 15:42 hadoop-hadoop-nodemanager-hadoop.log
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 15:48 hadoop-hadoop-namenode-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 15:48 hadoop-hadoop-datanode-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 690 Mar 18 15:48 hadoop-hadoop-secondarynamenode-hadoop.out
-rw-rw-r–. 1 hadoop hadoop 970190 Mar 18 15:48 hadoop-hadoop-datanode-hadoop.log
drwxr-xr-x. 2 hadoop hadoop 6 Mar 18 15:48 userlogs
-rw-rw-r–. 1 hadoop hadoop 572169 Mar 18 15:49 hadoop-hadoop-namenode-hadoop.log
-rw-rw-r–. 1 hadoop hadoop 656741 Mar 18 15:49 hadoop-hadoop-secondarynamenode-hadoop.log
[hadoop@hadoop logs]$ pwd
/usr/local/hadoop/hadoop-3.1.3/logs
[hadoop@hadoop logs]$ tail -20f hadoop-hadoop-namenode-hadoop.log
2022-03-18 15:48:39,521 INFO org.apache.hadoop.hdfs.StateChange: BLOCK* registerDatanode: from DatanodeRegistration(192.168.10.248:9866, datanodeUuid=daafd206-fdfe-44cc-a1fc-8ac1279c5cda, infoPort=9864, infoSecurePort=0, ipcPort=9867, storageInfo=lv=-57;cid=CID-f921bab0-7c73-44ef-bc61-ea81d176ec82;nsid=311459717;c=1647534325420) storage daafd206-fdfe-44cc-a1fc-8ac1279c5cda
2022-03-18 15:48:39,523 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/192.168.10.248:9866
2022-03-18 15:48:39,523 INFO org.apache.hadoop.hdfs.server.blockmanagement.BlockReportLeaseManager: Registered DN daafd206-fdfe-44cc-a1fc-8ac1279c5cda (192.168.10.248:9866).
2022-03-18 15:48:39,889 INFO org.apache.hadoop.hdfs.server.blockmanagement.DatanodeDescriptor: Adding new storage ID DS-6dd0b7dc-1fd0-488c-924b-76de306ac2cb for DN 192.168.10.248:9866
2022-03-18 15:48:40,062 INFO BlockStateChange: BLOCK* processReport 0xf15bae747aec7666: Processing first storage report for DS-6dd0b7dc-1fd0-488c-924b-76de306ac2cb from datanode daafd206-fdfe-44cc-a1fc-8ac1279c5cda
2022-03-18 15:48:40,065 INFO BlockStateChange: BLOCK* processReport 0xf15bae747aec7666: from storage DS-6dd0b7dc-1fd0-488c-924b-76de306ac2cb node DatanodeRegistration(192.168.10.248:9866, datanodeUuid=daafd206-fdfe-44cc-a1fc-8ac1279c5cda, infoPort=9864, infoSecurePort=0, ipcPort=9867, storageInfo=lv=-57;cid=CID-f921bab0-7c73-44ef-bc61-ea81d176ec82;nsid=311459717;c=1647534325420), blocks: 0, hasStaleStorage: false, processing time: 3 msecs, invalidatedBlocks: 0
2022-03-18 15:49:44,972 INFO org.apache.hadoop.hdfs.server.namenode.FSNamesystem: Roll Edit Log from 192.168.10.248
2022-03-18 15:49:44,972 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Rolling edit logs
2022-03-18 15:49:44,973 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Ending log segment 85, 85
2022-03-18 15:49:44,973 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Number of transactions: 2 Total time for transactions(ms): 2 Number of transactions batched in Syncs: 84 Number of syncs: 2 SyncTimes(ms): 130
2022-03-18 15:49:44,988 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Number of transactions: 2 Total time for transactions(ms): 2 Number of transactions batched in Syncs: 84 Number of syncs: 3 SyncTimes(ms): 144
2022-03-18 15:49:44,990 INFO org.apache.hadoop.hdfs.server.namenode.FileJournalManager: Finalizing edits file /home/hadoop_data/dfs/name/current/edits_inprogress_0000000000000000085 -> /home/hadoop_data/dfs/name/current/edits_0000000000000000085-0000000000000000086
2022-03-18 15:49:44,992 INFO org.apache.hadoop.hdfs.server.namenode.FSEditLog: Starting log segment at 87
2022-03-18 15:49:45,514 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Sending fileName: /home/hadoop_data/dfs/name/current/fsimage_0000000000000000083, fileSize: 533. Sent total: 533 bytes. Size of last segment intended to send: -1 bytes.
2022-03-18 15:49:45,641 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Sending fileName: /home/hadoop_data/dfs/name/current/edits_0000000000000000084-0000000000000000084, fileSize: 1048576. Sent total: 1048576 bytes. Size of last segment intended to send: -1 bytes.
2022-03-18 15:49:45,744 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Sending fileName: /home/hadoop_data/dfs/name/current/edits_0000000000000000085-0000000000000000086, fileSize: 42. Sent total: 42 bytes. Size of last segment intended to send: -1 bytes.
2022-03-18 15:49:46,668 INFO org.apache.hadoop.hdfs.server.common.Util: Combined time for file download and fsync to all disks took 0.00s. The file download took 0.00s at 0.00 KB/s. Synchronous (fsync) write to disk of /home/hadoop_data/dfs/name/current/fsimage.ckpt_0000000000000000086 took 0.00s.
2022-03-18 15:49:46,668 INFO org.apache.hadoop.hdfs.server.namenode.TransferFsImage: Downloaded file fsimage.ckpt_0000000000000000086 size 533 bytes.
2022-03-18 15:49:46,684 INFO org.apache.hadoop.hdfs.server.namenode.NNStorageRetentionManager: Going to retain 2 images with txid >= 83
2022-03-18 15:49:46,684 INFO org.apache.hadoop.hdfs.server.namenode.NNStorageRetentionManager: Purging old image FSImageFile(file=/home/hadoop_data/dfs/name/current/fsimage_0000000000000000081, cpktTxId=0000000000000000081)
这就是namenode启动成功,如查格式化两次就会出现datanode启动不成功,这是clusterID两次不致造成的,可以进入
-rw-rw-r–. 1 hadoop hadoop 229 Mar 18 15:48 VERSION
drwx——. 4 hadoop hadoop 54 Mar 18 15:48 BP-301391941-192.168.10.248-1647534325420
[root@hadoop current]# cat VERSION
#Fri Mar 18 15:48:38 CST 2022
storageID=DS-6dd0b7dc-1fd0-488c-924b-76de306ac2cb
clusterID=CID-f921bab0-7c73-44ef-bc61-ea81d176ec82
cTime=0
datanodeUuid=daafd206-fdfe-44cc-a1fc-8ac1279c5cda
storageType=DATA_NODE
layoutVersion=-57
[root@hadoop current]# pwd
/home/hadoop_data/dfs/data/current
修改clusterID和namenode节点的clusterID一样后,在重启hadoop服务
现在伪分布式hadoop集群已经部署成功了,如果启动hadoop的时候遇到了问题,可以查看对应的log文件查看是由什么问题引起的。一般的问题如,未设置JAVA_HOME hadoopdata目录不存在,或者无权限等等。
现要在可以进入hadoop组件hdfs的UI界面:
现要在可以进入hadoop组件yarn的UI界面:
可能安装过成会遇到各样的问题,可是查看日志和搜索或是去官网站都可以找到解决的**,我只是把做的过程记录出来了,以备后需。
拓展知识:
kb3189866
有的机器升级不仅仅一次不成功,有时候反复升级都是这样,这样的情况我在升级补丁的时候也遇到过!比如:升级W10周年版本的14393(kb3189866)的时候更新到45%就卡住了,没办法进一步的往下进行,最后还是在论坛里找到升级的下载包解决了!
原创文章,作者:九贤生活小编,如若转载,请注明出处:http://www.wangguangwei.com/42372.html
相关推荐
-
禁用数字签名 win7
前沿拓展: 禁用数字签名 win7 64位win7禁用驱动程序签名强制 其实想要在64位win7中使用未有签名的驱动程序还是有很多方法的,如上图中,开机之后在登录等待界面按下F…
-
联想笔记本进入bios设置按哪个键(联想笔记本怎样进入bios)
联想笔记本进入bios设置按哪个键(联想笔记本怎样进入bios) 老铁们好啊,今天小编给大家分享下我们在使用电脑过程中会遇到的一些问题故障该如何处理,热门电脑游戏需求配置,电脑使用…
-
笔记本对比桌面显卡天梯图:笔记本显卡对比桌面显卡天梯图
笔记本对比桌面显卡天梯图:笔记本显卡对比桌面显卡天梯图 大家好,今天小编来为大家解答笔记本对比桌面显卡天梯图:笔记本显卡对比桌面显卡天梯图这个问题,笔记本对比桌面显卡天梯图:笔记本…
-
i74790显卡(i74790显卡性能)
介绍i7 4790K i7 4790K是英特尔Haswell微架构中的一款处理器,是当年Intel的顶级四核处理器。它的基础频率为4.0GHz,最大睿频可达4.4GHz,具有八线程…
-
荣耀赵明专访:青出于蓝而胜于蓝 以消费者为中心 像苹果致敬 然后超越
【TechWeb】2023年3月6日,在荣耀Magic5系列及全场景新品发布会上,荣耀正式发布全新一代旗舰手机产品——荣耀Magic5系列,包括荣耀Magic5、荣耀Magic5 Pro以及荣耀Magic5 至臻版三款产品。经过两年的蓄力和
-
2017年3500元主机配置(3500元电脑主机配置单)
2017年3500元主机配置(3500元电脑主机配置单) 老铁们好啊,今天小编给大家分享下我们在使用电脑过程中会遇到的一些问题故障该如何处理,热门电脑游戏需求配置,电脑使用的一些小…
-
internet explorer无法打开
前沿拓展: internet explor C 、“地址栏” 整理 | 王启隆 透过「历史上的今天」,从过去看未来,从现在亦可以改变未来。 今天是 2022 年 10 月 19 日…
-
顶配电脑机箱配置(电脑机箱的主要配置有什么)
顶配电脑机箱配置-为你的电脑保驾护航 电脑机箱是电脑组装的重要组成部分之一,其大小、风扇数量、散热性能、功能性都会对电脑性能产生直接的影响。所以,在选择电脑机箱时,我们需要考虑各种…
-
dell笔记本重装系统找不到硬盘:小米笔记本重装系统找不到硬盘
大家好,dell笔记本重装系统找不到硬盘:小米笔记本重装系统找不到硬盘相信很多的网友都不是很明白,包括dell笔记本重装系统找不到硬盘:小米笔记本重装系统找不到硬盘也是一样,不过没…
-
笔记本电脑一般多少钱一台(学生笔记本电脑一般多少钱一台)
一台笔记本电脑多少钱? 一般的话买个7000~8500的不容易被淘汰 一台笔记本电脑要多少钱? 买个三千多的吧 笔记本电脑一般多少钱一台 再过两个月,将有大批学子步入大学校园,开启…