
前沿拓展:
u**scan.sys
试试把你的电脑重做系统吧,做系统的光盘一定不要和你现在使用的系统是一张盘,换张新盘做下系统!这样应该可以解决问
在 Linux 文件系统就采用了位图的方式来管理空闲空间,不仅用于数据空闲块的管理,还用于 inode 空闲块的管理,因为 inode 也是存储在磁盘的,自然也要有对其管理。


文件系统的结构
前面提到 Linux 是用位图的方式管理空闲空间,用户在创建一个新文件时,Linux 内核会通过 inode 的位图找到空闲可用的 inode,并进行分配。要存储数据时,会通过块的位图找到空闲的块,并分配,但仔细计算一下还是有问题的。
数据块的位图是放在磁盘块里的,假设是放在一个块里,一个块 4K,每位表示一个数据块,共可以表示 4 * 1024 * 8 = 2^15 个空闲块,由于 1 个数据块是 4K 大小,那么最大可以表示的空间为 2^15 * 4 * 1024 = 2^27 个 byte,也就是 128M。
也就是说按照上面的结构,如果采用「一个块的位图 + 一系列的块」,外加「一个块的 inode 的位图 + 一系列的 inode 的结构」能表示的最大空间也就 128M,这太少了,现在很多文件都比这个大。
在 Linux 文件系统,把这个结构称为一个块组,那么有 N 多的块组,就能够表示 N 大的文件。
下图给出了 Linux Ext2 整个文件系统的结构和块组的内容,文件系统都由大量块组组成,在硬盘上相继排布:

最前面的第一个块是引导块,在系统启动时用于启用引导,接着后面就是一个一个连续的块组了,块组的内容如下:
超级块,包含的是文件系统的重要信息,比如 inode 总个数、块总个数、每个块组的 inode 个数、每个块组的块个数等等。
块组描述符,包含文件系统中各个块组的状态,比如块组中空闲块和 inode 的数目等,每个块组都包含了文件系统中「所有块组的组描述符信息」。
数据位图和 inode 位图, 用于表示对应的数据块或 inode 是空闲的,还是被使用中。
inode 列表,包含了块组中所有的 inode,inode 用于保存文件系统中与各个文件和目录相关的所有元数据。
数据块,包含文件的有用数据。
你可以会发现每个块组里有很多重复的信息,比如超级块和块组描述符表,这两个都是全局信息,而且非常的重要,这么做是有两个原因:
如果系统崩溃破坏了超级块或块组描述符,有关文件系统结构和内容的所有信息都会丢失。如果有冗余的副本,该信息是可能恢复的。
通过使文件和管理数据尽可能接近,减少了磁头寻道和旋转,这可以提高文件系统的性能。
不过,Ext2 的后续版本采用了稀疏技术。该做法是,超级块和块组描述符表不再存储到文件系统的每个块组中,而是只写入到块组 0、块组 1 和其他 ID 可以表示为 3、 5、7 的幂的块组中。

目录的存储
在前面,我们知道了一个普通文件是如何存储的,但还有一个特殊的文件,经常用到的目录,它是如何保存的呢?
基于 Linux 一切皆文件的设计思想,目录其实也是个文件,你甚至可以通过 vim 打开它,它也有 inode,inode 里面也是指向一些块。
和普通文件不同的是,普通文件的块里面保存的是文件数据,而目录文件的块里面保存的是目录里面一项一项的文件信息。
在目录文件的块中,最简单的保存格式就是列表,就是一项一项地将目录下的文件信息(如文件名、文件 inode、文件类型等)列在表里。
列表中每一项就代表该目录下的文件的文件名和对应的 inode,通过这个 inode,就可以找到真正的文件。

目录格式哈希表
通常,第一项是「.」,表示当前目录,第二项是「..」,表示上一级目录,接下来就是一项一项的文件名和 inode。
如果一个目录有超级多的文件,我们要想在这个目录下找文件,按照列表一项一项的找,效率就不高了。
于是,保存目录的格式改成哈希表,对文件名进行哈希计算,把哈希值保存起来,如果我们要查找一个目录下面的文件名,可以通过名称取哈希。如果哈希能够匹配上,就说明这个文件的信息在相应的块里面。
Linux 系统的 ext 文件系统就是采用了哈希表,来保存目录的内容,这种方法的优点是查找非常迅速,插入和删除也较简单,不过需要一些预备措施来避免哈希冲突。
目录查询是通过在磁盘上反复搜索完成,需要不断地进行 I/O **作,开销较大。所以,为了减少 I/O **作,把当前使用的文件目录缓存在内存,以后要使用该文件时只要在内存中**作,从而降低了磁盘**作次数,提高了文件系统的访问速度。

软链接和硬链接
有时候我们希望给某个文件取个别名,那么在 Linux 中可以通过硬链接(Hard Link)和软链接(Symbolic Link)的方式来实现,它们都是比较特殊的文件,但是实现方式也是不相同的。
硬链接是多个目录项中的「索引节点」指向一个文件,也就是指向同一个 inode,但是 inode 是不可能跨越文件系统的,每个文件系统都有各自的 inode 数据结构和列表,所以硬链接是不可用于跨文件系统的。由于多个目录项都是指向一个 inode,那么只有删除文件的所有硬链接以及源文件时,系统才会彻底删除该文件。

硬链接
软链接相当于重新创建一个文件,这个文件有**的 inode,但是这个文件的内容是另外一个文件的路径,所以访问软链接的时候,实际上相当于访问到了另外一个文件,所以软链接是可以跨文件系统的,甚至目标文件被删除了,链接文件还是在的,只不过指向的文件找不到了而已。

软链接

文件 I/O
文件的读写方式各有千秋,对于文件的 I/O 分类也非常多,常见的有
缓冲与非缓冲 I/O
直接与非直接 I/O
阻塞与非阻塞 I/O VS 同步与异步 I/O
接下来,分别对这些分类讨论讨论。
缓冲与非缓冲 I/O
文件**作的标准库是可以实现数据的缓存,那么根据「是否利用标准库缓冲」,可以把文件 I/O 分为缓冲 I/O 和非缓冲 I/O:
缓冲 I/O,利用的是标准库的缓存实现文件的加速访问,而标准库再通过系统调用访问文件。
非缓冲 I/O,直接通过系统调用访问文件,不经过标准库缓存。
这里所说的「缓冲」特指标准库内部实现的缓冲。
比方说,很多程序遇到换行时才真正输出,而换行前的内容,其实就是被标准库暂时缓存了起来,这样做的目的是,减少系统调用的次数,毕竟系统调用是有 CPU 上下文切换的开销的。
直接与非直接 I/O
我们都知道磁盘 I/O 是非常慢的,所以 Linux 内核为了减少磁盘 I/O 次数,在系统调用后,会把用户数据拷贝到内核中缓存起来,这个内核缓存空间也就是「页缓存」,只有当缓存满足某些条件的时候,才发起磁盘 I/O 的请求。
那么,根据是「否利用**作系统的缓存」,可以把文件 I/O 分为直接 I/O 与非直接 I/O:
直接 I/O,不会发生内核缓存和用户程序之间数据**,而是直接经过文件系统访问磁盘。
非直接 I/O,读**作时,数据从内核缓存中拷贝给用户程序,写**作时,数据从用户程序拷贝给内核缓存,再由内核决定什么时候写入数据到磁盘。
如果你在使用文件**作类的系统调用函数时,指定了 O_DIRECT 标志,则表示使用直接 I/O。如果没有设置过,默认使用的是非直接 I/O。
如果用了非直接 I/O 进行写数据**作,内核什么情况下才会把缓存数据写入到磁盘?
以下几种场景会触发内核缓存的数据写入磁盘:
在调用 write 的最后,当发现内核缓存的数据太多的时候,内核会把数据写到磁盘上;
用户主动调用 sync,内核缓存会刷到磁盘上;
当内存十分紧张,无法再分配页面时,也会把内核缓存的数据刷到磁盘上;
内核缓存的数据的缓存时间超过某个时间时,也会把数据刷到磁盘上;
阻塞与非阻塞 I/O VS 同步与异步 I/O
为什么把阻塞 / 非阻塞与同步与异步放一起说的呢?因为它们确实非常相似,也非常容易混淆,不过它们之间的关系还是有点微妙的。
先来看看阻塞 I/O,当用户程序执行 read ,线程会被阻塞,一直等到内核数据准备好,并把数据从内核缓冲区拷贝到应用程序的缓冲区中,当拷贝过程完成,read 才会返回。
注意,阻塞等待的是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程。过程如下图:

阻塞 I/O
知道了阻塞 I/O ,来看看非阻塞 I/O,非阻塞的 read 请求在数据未准备好的情况下立即返回,可以继续往下执行,此时应用程序不断轮询内核,直到数据准备好,内核将数据拷贝到应用程序缓冲区,read 调用才可以获取到结果。过程如下图:
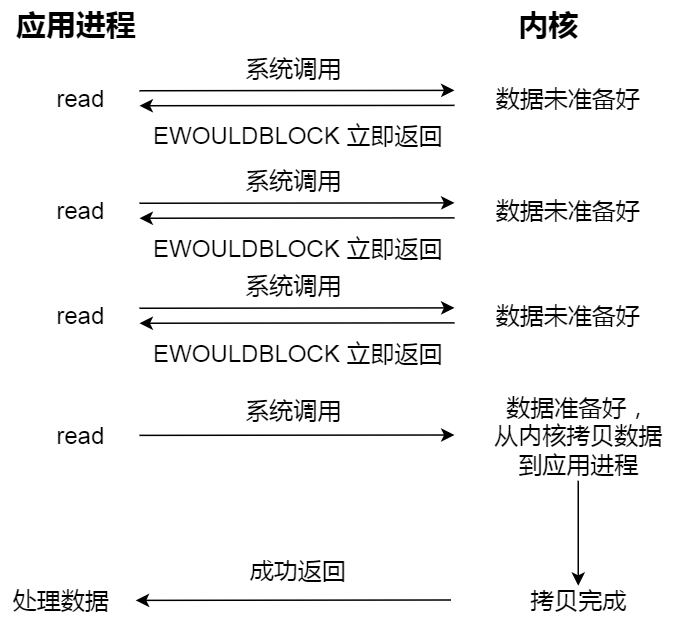
非阻塞 I/O
注意,这里最后一次 read 调用,获取数据的过程,是一个同步的过程,是需要等待的过程。这里的同步指的是内核态的数据拷贝到用户程序的缓存区这个过程。
举个例子,访问管道或 socket 时,如果设置了 O_NONBLOCK 标志,那么就表示使用的是非阻塞 I/O 的方式访问,而不做任何设置的话,默认是阻塞 I/O。
应用程序每次轮询内核的 I/O 是否准备好,感觉有点傻乎乎,因为轮询的过程中,应用程序啥也做不了,只是在循环。
为了解决这种傻乎乎轮询方式,于是 I/O 多路复用技术就出来了,如 select、poll,它是通过 I/O **分发,当内核数据准备好时,再以**通知应用程序进行**作。
这个做法大大改善了应用进程对 CPU 的利用率,在没有被通知的情况下,应用进程可以使用 CPU 做其他的事情。
下图是使用 select I/O 多路复用过程。注意,read 获取数据的过程(数据从内核态拷贝到用户态的过程),也是一个同步的过程,需要等待:

I/O 多路复用
实际上,无论是阻塞 I/O、非阻塞 I/O,还是基于非阻塞 I/O 的多路复用都是同步调用。因为它们在 read 调用时,内核将数据从内核空间拷贝到应用程序空间,过程都是需要等待的,也就是说这个过程是同步的,如果内核实现的拷贝效率不高,read 调用就会在这个同步过程中等待比较长的时间。
而真正的异步 I/O 是「内核数据准备好」和「数据从内核态拷贝到用户态」这两个过程都不用等待。
当我们发起 aio_read 之后,就立即返回,内核自动将数据从内核空间拷贝到应用程序空间,这个拷贝过程同样是异步的,内核自动完成的,和前面的同步**作不一样,应用程序并不需要主动发起拷贝动作。过程如下图:
异步 I/O
下面这张图,小编综合来说了以上几种 I/O 模型:

在前面我们知道了,I/O 是分为两个过程的:
数据准备的过程;
数据从内核空间拷贝到用户进程缓冲区的过程;
阻塞 I/O 会阻塞在「过程 1 」和「过程 2」,而非阻塞 I/O 和基于非阻塞 I/O 的多路复用只会阻塞在「过程 2」,所以这三个都可以认为是同步 I/O。
异步 I/O 则不同,「过程 1 」和「过程 2 」都不会阻塞。
用故事去理解这几种 I/O 模型
举个你去饭堂吃饭的例子,你好比用户程序,饭堂好比**作系统。
阻塞 I/O 好比,你去饭堂吃饭,但是饭堂的菜还没做好,第二你就一直在那里等啊等,等了好长一段时间终于等到饭堂阿姨把菜端了出来(数据准备的过程),但是你还得继续等阿姨把菜(内核空间)打到你的饭盒里(用户空间),经历完这两个过程,你才可以离开。
非阻塞 I/O 好比,你去了饭堂,问阿姨菜做好了没有,阿姨告诉你没,你就离开了,过几十分钟,你又来饭堂问阿姨,阿姨说做好了,于是阿姨帮你把菜打到你的饭盒里,这个过程你是得等待的。
基于非阻塞的 I/O 多路复用好比,你去饭堂吃饭,发现有一排窗口,饭堂阿姨告诉你这些窗口都还没做好菜,等做好了再通知你,于是等啊等(select 调用中),过了一会阿姨通知你菜做好了,但是不知道哪个窗口的菜做好了,你自己看吧。于是你只能一个一个窗口去确认,后面发现 5 号窗口菜做好了,于是你让 5 号窗口的阿姨帮你打菜到饭盒里,这个打菜的过程你是要等待的,虽然时间不长。打完菜后,你自然就可以离开了。
异步 I/O 好比,你让饭堂阿姨将菜做好并把菜打到饭盒里后,把饭盒送到你面前,整个过程你都不需要任何等待。

拓展知识:
原创文章,作者:九贤生活小编,如若转载,请注明出处:http://www.wangguangwei.com/70004.html
相关推荐
-
i76700k内存选择(i76700K支持内存频率)
为i7 6700k选择内存的重要性 当你在升级或组装一台电脑时,选择适当的内存是非常重要的。i7 6700k是一款优秀的CPU,但是如果没有正确的内存支持,其性能也会受到影响。因此…
-
启动盘制作-u盘制作macos系统启动盘
本文目录1、u盘制作macos系统启动盘?2、u盘魔术师启动盘制作和使用?3、移动硬盘制作pe启动盘?4、怎么把U盘制作成启动盘(U盘启动)?5、f11u盘启动盘怎么做?1、u盘制作macos系统启动盘?下载得到DiskMaker_X.dmg,双击挂载DiskMaker_X.dmg后,将DiskMaker X拖放到应用程序文件夹中。 1、点击运行DiskMaker X。 2、选择要制作成安装盘
-
笔记本重装系统(笔记本重装系统多少钱一次)
笔记本电脑重装系统要多少钱? 安装系统一般是20–50元,其实自己也可以安装的,方法是: 1、第一制作好u盘启动盘,接着将该u盘启动盘插入电脑u**接口,按开机启动快捷…
-
平板刷机王(平板刷机王手机版)
前沿拓展: 记者 | 龙力 编辑 | 8月5日,华大九天(301269.SZ)开盘之后股价稳步上扬,随后成功实现20CM涨停,截至收盘依然有1.17万手的封单。至此,该股在上市第6…
-
如何创建Excel下拉列表(提高数据的准确性)
Excel下拉列表是Excel中的一种数据校验功能,用于限制用户在单元格中输入的数据类型。使用有效的下拉列表可以节省大量的时间,并且可以提高数据的准确性。 下拉列表的优势 第一,E…
-
联想s5progt参数配置(联想s5progt刷机包)
这篇文章给大家聊聊关于联想s5progt参数配置(联想s5progt刷机包),以及联想s5progt参数配置(联想s5progt刷机包)对应的知识点,希望对各位有所帮助,不要忘了收藏本站哦。1198元!联想S5ProGT版发布:升级骁龙660AIE12月18日下午2点,联想将在北京·联想全球总部举办新品发布会,将
-
4k游戏电脑配置(4k显示器对电脑配置的要求)
什么是4K游戏电脑配置 4K游戏电脑配置是指可以支持游戏在4K分辨率下运行的硬件设备。4K分辨率是指每个屏幕水平像素为3840个,垂直像素为2160个,这比常规的1080P分辨率高…
-
windows7 激活
前沿拓展: 最近有用户问WIN7系统怎么激活,这个算是很早的一个问题了,只是记得未激活的系统,桌面右下角会提示“Windows7 内部版本 XXXX 此Windows 副本不是正版…
-
神舟笔记本官网(神舟笔记本官网)
神舟笔记本官网 不少朋友需要购买游戏本,或者是其应用(学习做视频、虚拟机、3D建模和渲染等)要求用到高性能本,但是预算只有5000元左右。对于这样的意向购机者,基本就只有买游戏本中…
-
2017打游戏怎么配主机
2017打游戏怎么配主机 老铁们好啊,今天小编给大家分享下我们在使用电脑过程中会遇到的一些问题故障该如何处理,热门游戏电脑需求配置,电脑使用的一些小技巧等内容 戴尔灵越系列所有型号…